author: Juma Shafara date: "2024-08-08" title: Convolution Neural Networks keywords: [Training Two Parameter, Mini-Batch Gradient Decent, Training Two Parameter Mini-Batch Gradient Decent] description: In this lab, you will review how to make a prediction in several different ways by using PyTorch.

Objective for this Notebook - Learn about Convolution.
- Leran Determining the Size of Output.
- Learn Stride, Zero Padding
- Learn about Convolution.
- Leran Determining the Size of Output.
- Learn Stride, Zero Padding
Table of Contents
In this lab, you will study convolution and review how the different operations change the relationship between input and output.
Estimated Time Needed: 25 min
Preparation
Import the following libraries:
Convolution is a linear operation similar to a linear equation, dot product, or matrix multiplication. Convolution has several advantages for analyzing images. As discussed in the video, convolution preserves the relationship between elements, and it requires fewer parameters than other methods.
You can see the relationship between the different methods that you learned:
In convolution, the parameter w is called a kernel. You can perform convolution on images where you let the variable image denote the variable X and w denote the parameter.
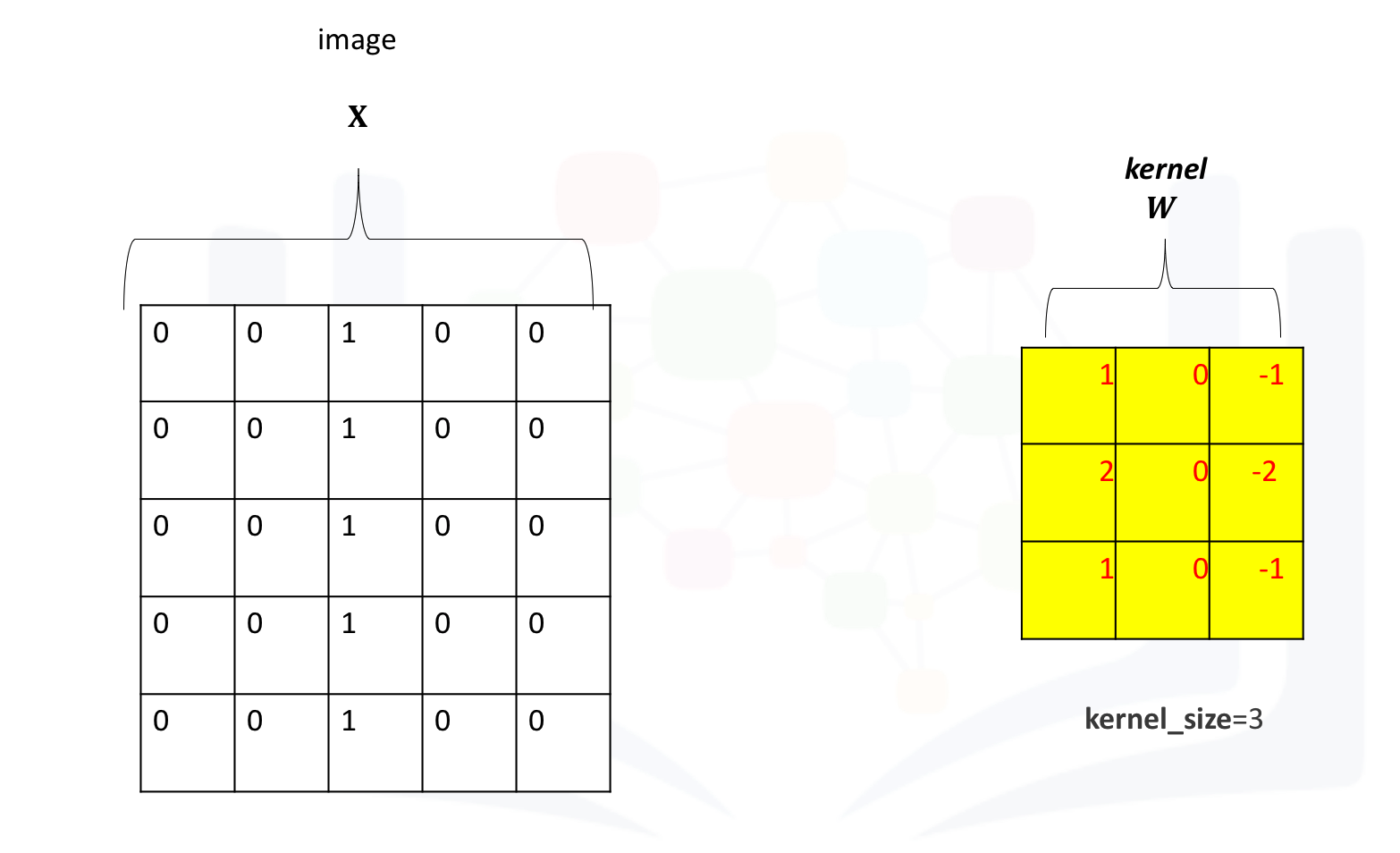
Create a two-dimensional convolution object by using the constructor Conv2d, the parameter in_channels and out_channels will be used for this section, and the parameter kernel_size will be three.
Because the parameters in nn.Conv2d are randomly initialized and learned through training, give them some values.
Create a dummy tensor to represent an image. The shape of the image is (1,1,5,5) where:
(number of inputs, number of channels, number of rows, number of columns )
Set the third column to 1:
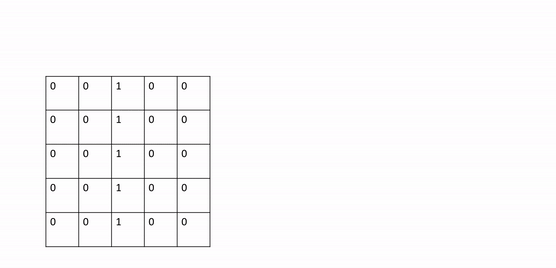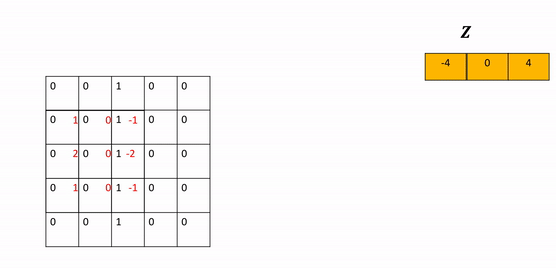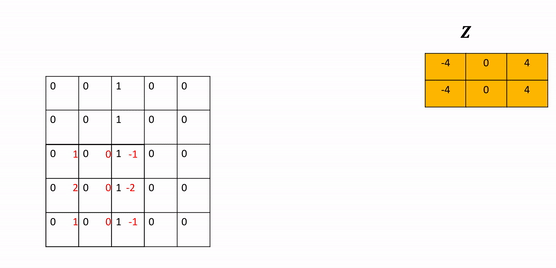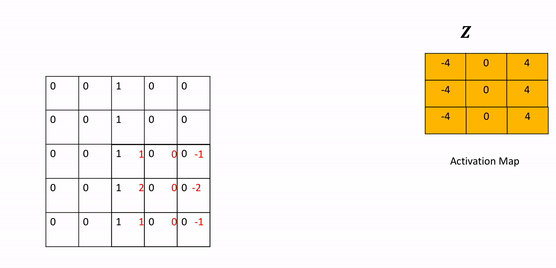
Call the object conv on the tensor image as an input to perform the convolution and assign the result to the tensor z.
The following animation illustrates the process, the kernel performs at the element-level multiplication on every element in the image in the corresponding region. The values are then added together. The kernel is then shifted and the process is repeated.
The size of the output is an important parameter. In this lab, you will assume square images. For rectangular images, the same formula can be used in for each dimension independently.
Let M be the size of the input and K be the size of the kernel. The size of the output is given by the following formula:
Create a kernel of size 2:
Create an image of size 2:
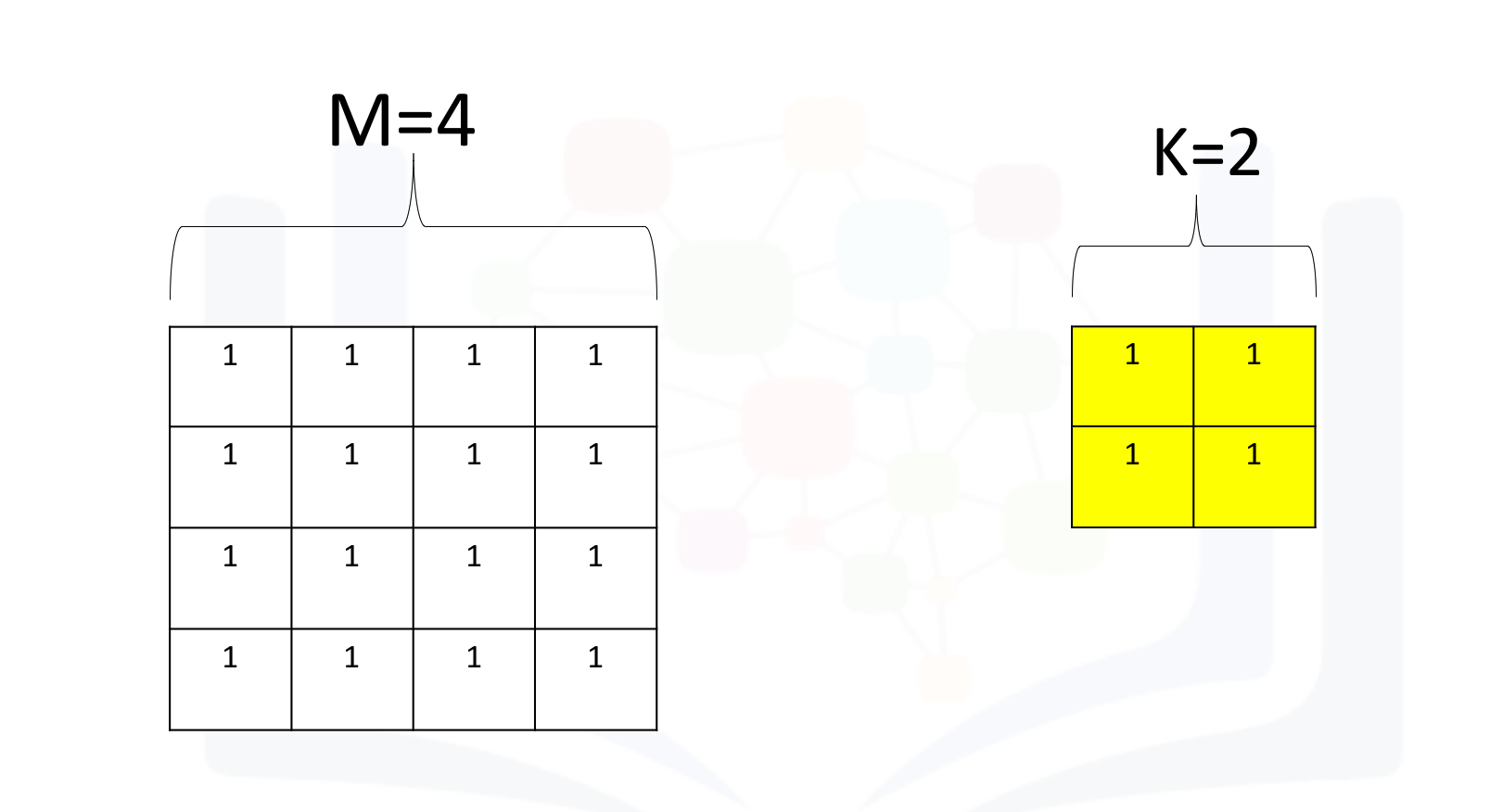
The following equation provides the output:
The following animation illustrates the process: The first iteration of the kernel overlay of the images produces one output. As the kernel is of size K, there are M-K elements for the kernel to move in the horizontal direction. The same logic applies to the vertical direction.
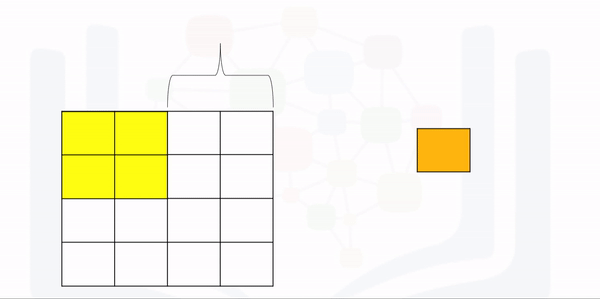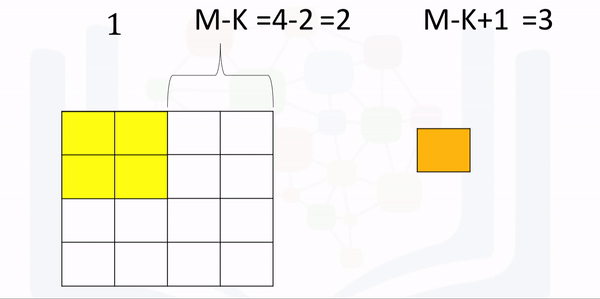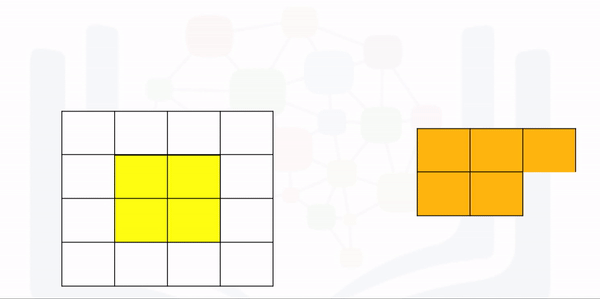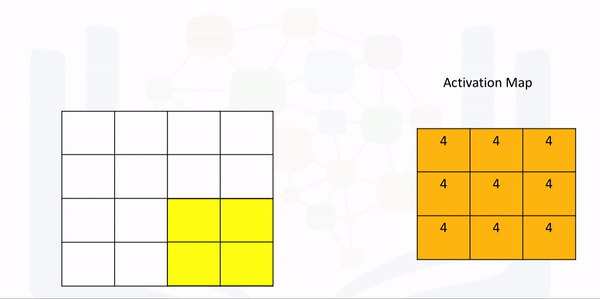
Perform the convolution and verify the size is correct:
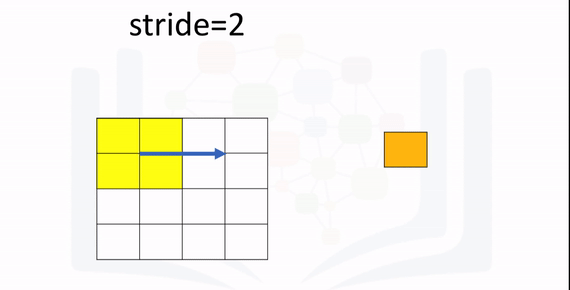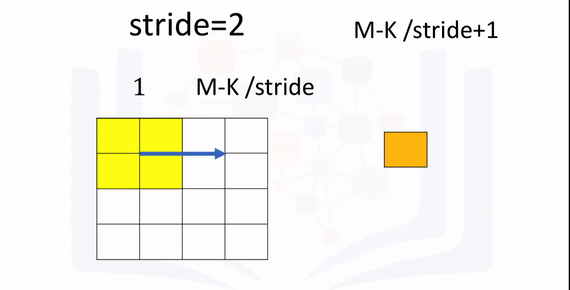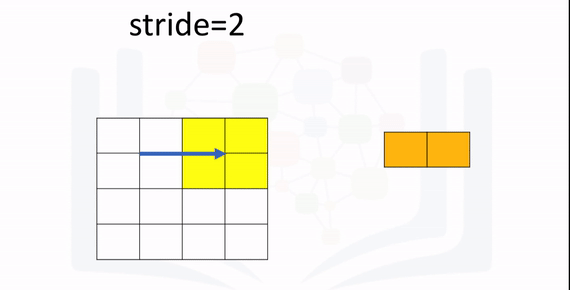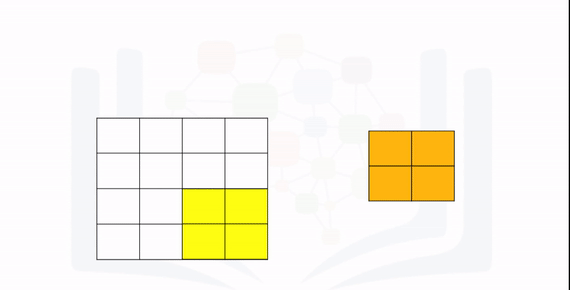
The parameter stride changes the number of shifts the kernel moves per iteration. As a result, the output size also changes and is given by the following formula:
Create a convolution object with a stride of 2:
For an image with a size of 4, calculate the output size:
The following animation illustrates the process: The first iteration of the kernel overlay of the images produces one output. Because the kernel is of size K, there are M-K=2 elements. The stride is 2 because it will move 2 elements at a time. As a result, you divide M-K by the stride value 2:
Perform the convolution and verify the size is correct:
As you apply successive convolutions, the image will shrink. You can apply zero padding to keep the image at a reasonable size, which also holds information at the borders.
In addition, you might not get integer values for the size of the kernel. Consider the following image:
Try performing convolutions with the kernel_size=2 and a stride=3. Use these values:
You can add rows and columns of zeros around the image. This is called padding. In the constructor Conv2d, you specify the number of rows or columns of zeros that you want to add with the parameter padding.
For a square image, you merely pad an extra column of zeros to the first column and the last column. Repeat the process for the rows. As a result, for a square image, the width and height is the original size plus 2 x the number of padding elements specified. You can then determine the size of the output after subsequent operations accordingly as shown in the following equation where you determine the size of an image after padding and then applying a convolutions kernel of size K.
Consider the following example:
The process is summarized in the following animation:
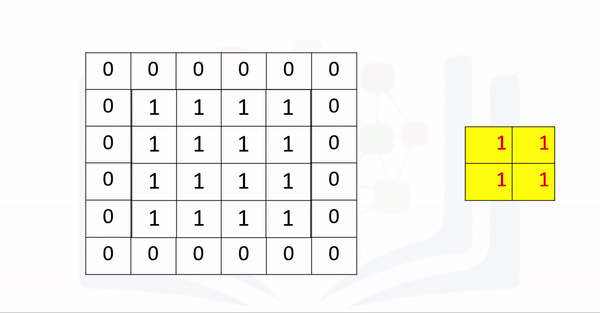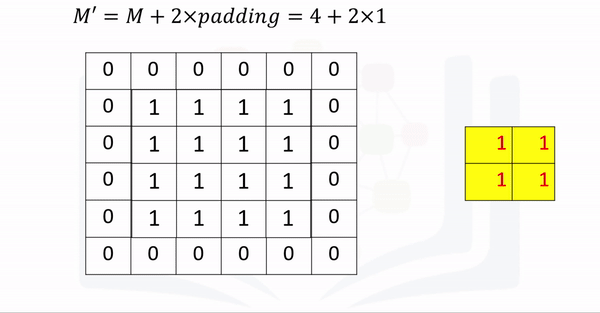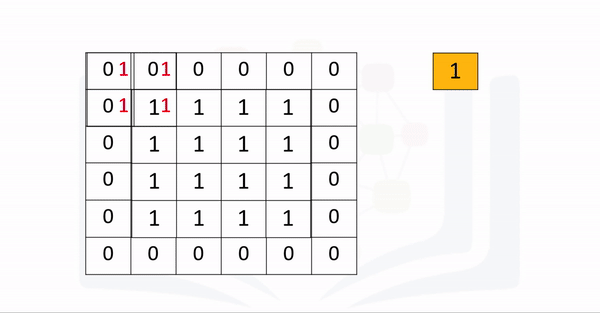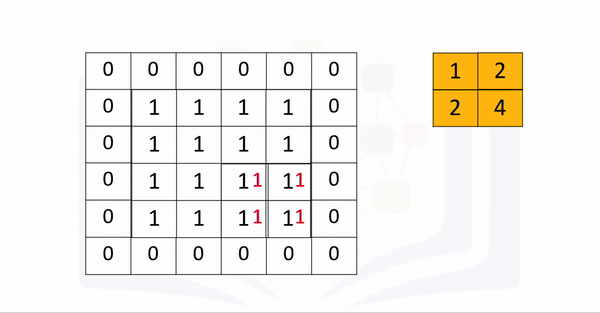
A kernel of zeros with a kernel size=3 is applied to the following image:
Question: Without using the function, determine what the outputs values are as each element:
Double-click here for the solution.
Question: Use the following convolution object to perform convolution on the tensor Image:
Double-click here for the solution.
Question: You have an image of size 4. The parameters are as follows kernel_size=2,stride=2. What is the size of the output?