author: Juma Shafara date: "2024-08-12" title: Activation function and Maxpooling keywords: [Training Two Parameter, Mini-Batch Gradient Decent, Training Two Parameter Mini-Batch Gradient Decent] description: In this lab, you will learn two important components in building a convolutional neural network.

Objective for this Notebook 1. Learn how to apply an activation function.
2. Learn about max pooling
1. Learn how to apply an activation function.
2. Learn about max pooling
Table of Contents
In this lab, you will learn two important components in building a convolutional neural network. The first is applying an activation function, which is analogous to building a regular network. You will also learn about max pooling. Max pooling reduces the number of parameters and makes the network less susceptible to changes in the image.
Estimated Time Needed: 25 min
Import the following libraries:
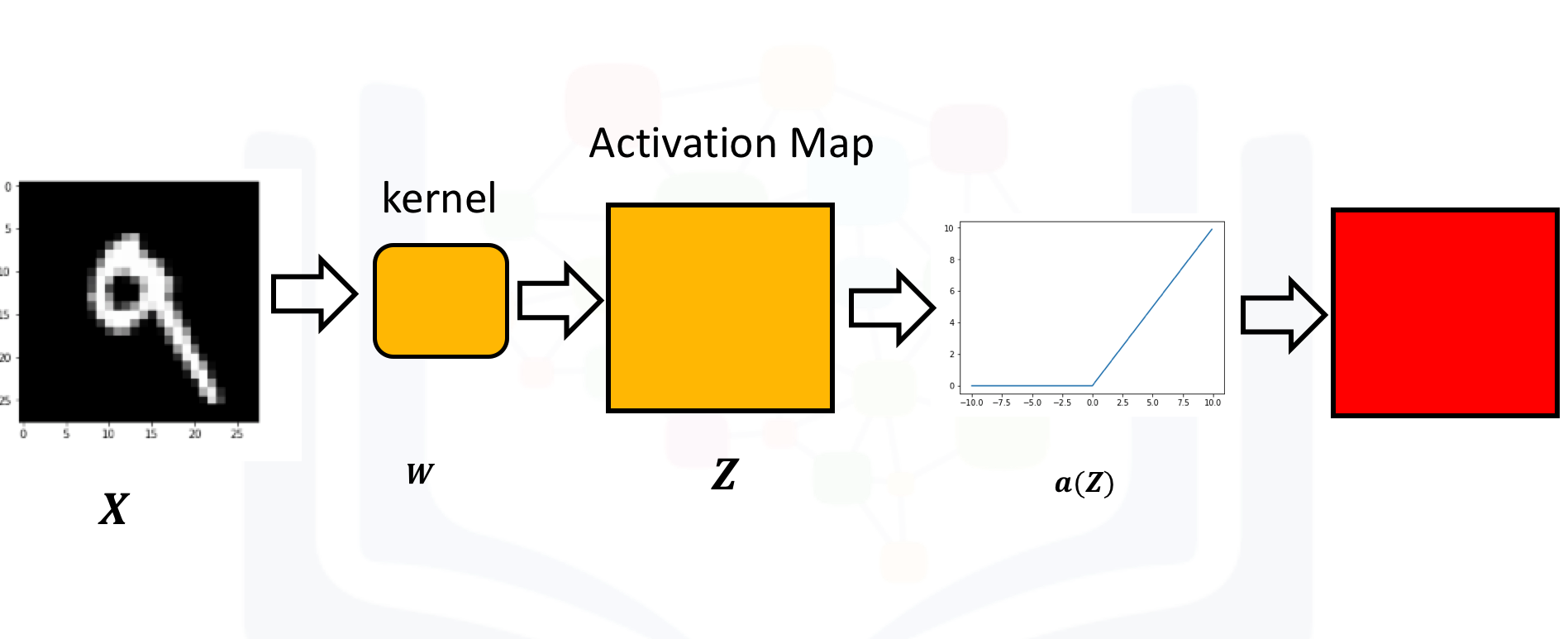
Just like a neural network, you apply an activation function to the activation map as shown in the following image:
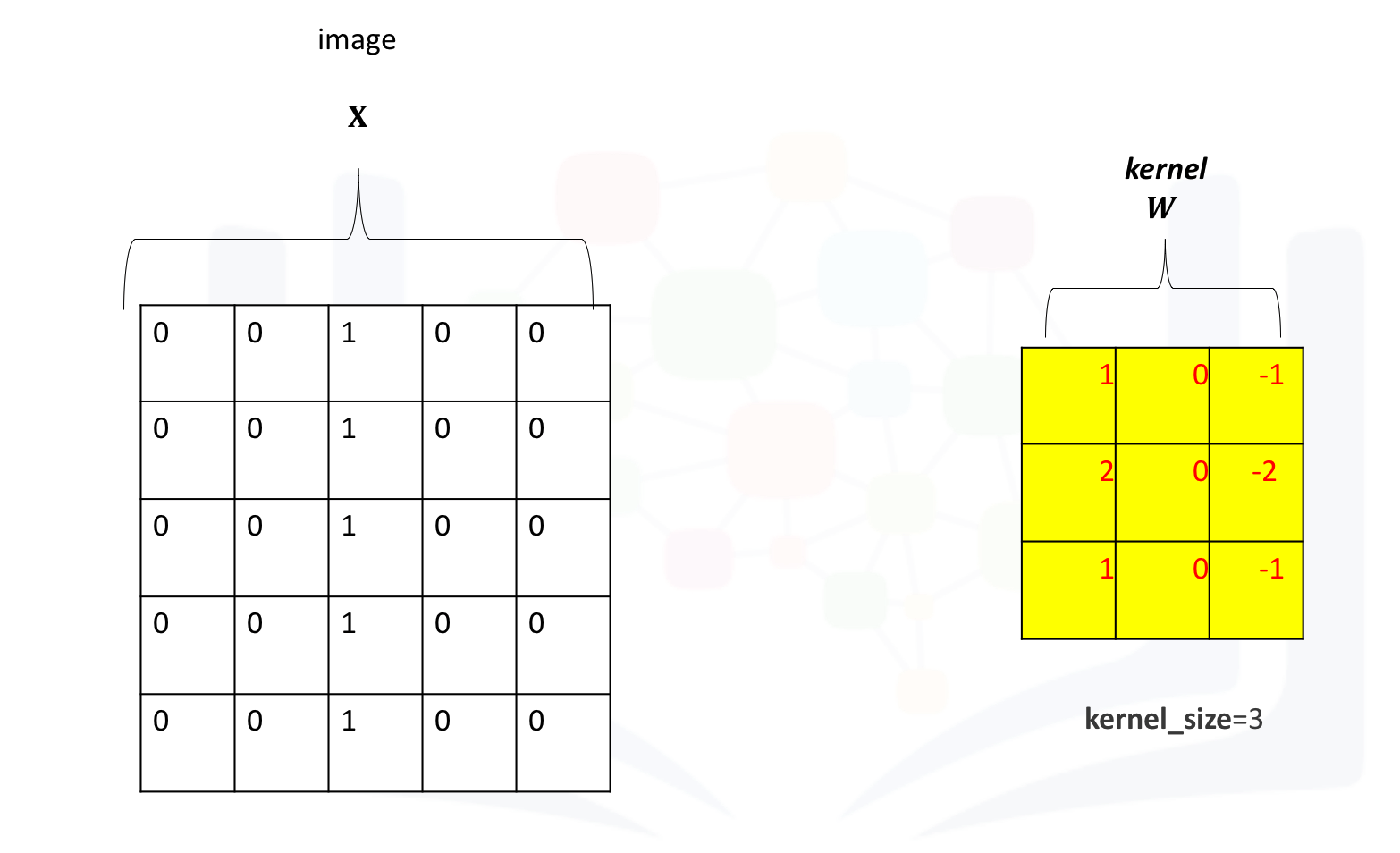
Create a kernel and image as usual. Set the bias to zero:
The following image shows the image and kernel:
Apply convolution to the image:
Apply the activation function to the activation map. This will apply the activation function to each element in the activation map.
The process is summarized in the the following figure. The Relu function is applied to each element. All the elements less than zero are mapped to zero. The remaining components do not change.
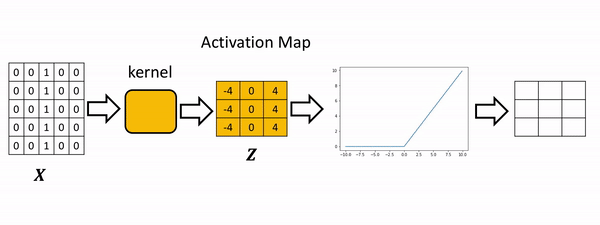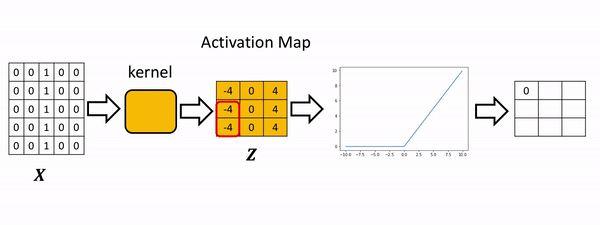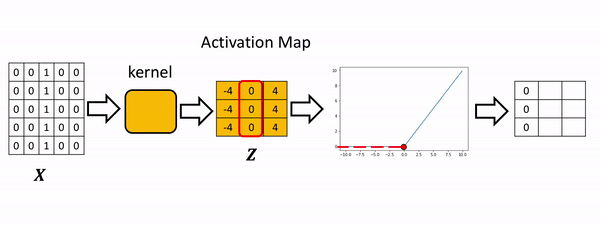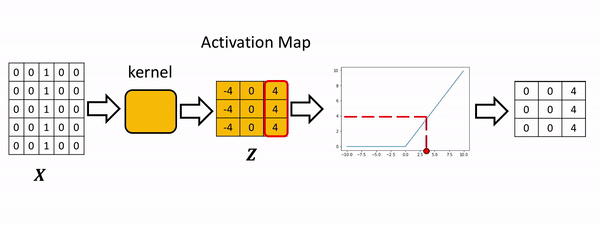
Consider the following image:
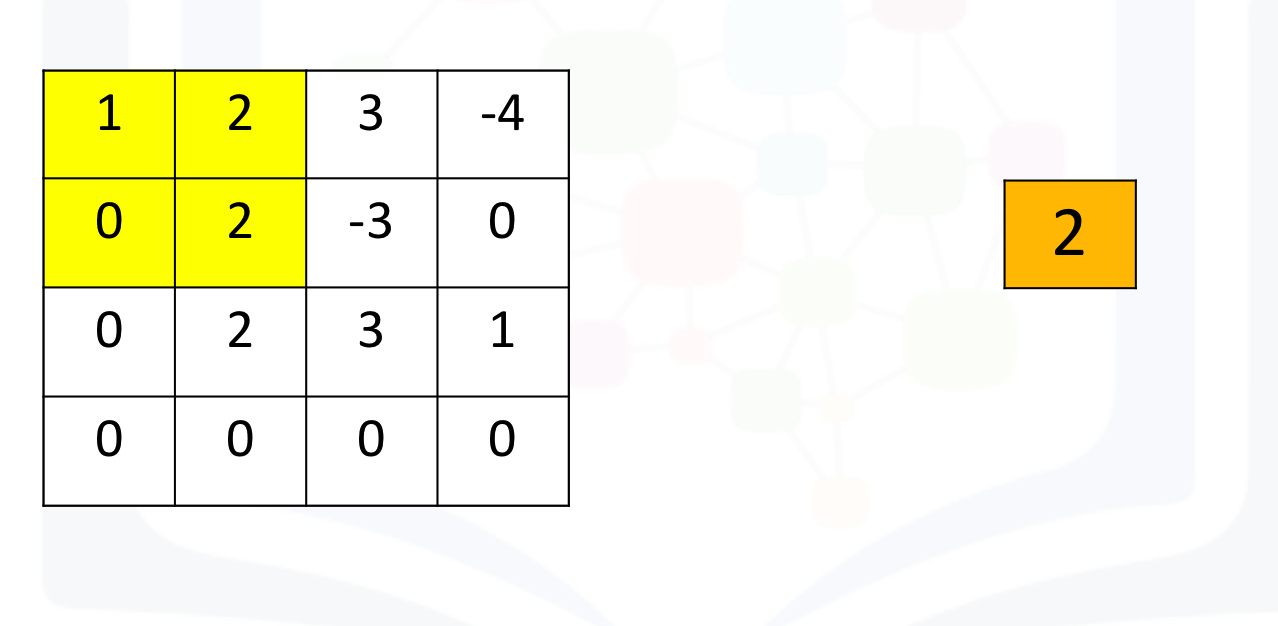
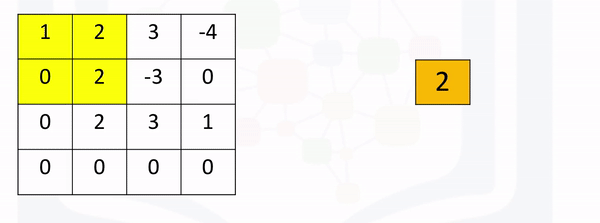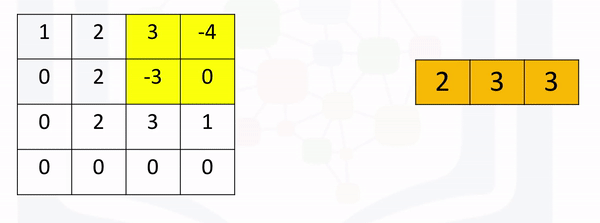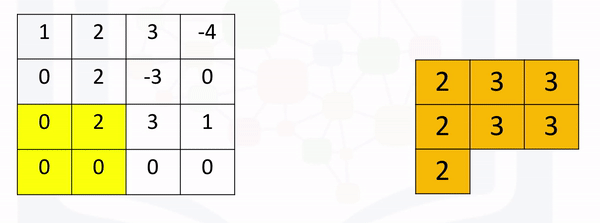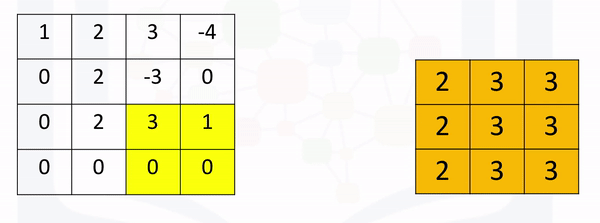
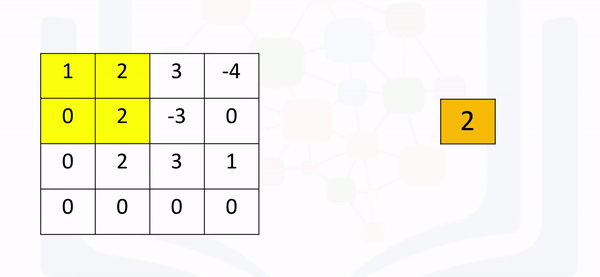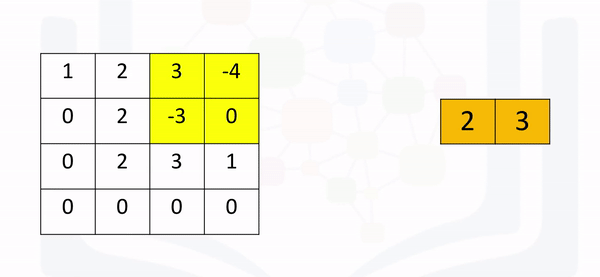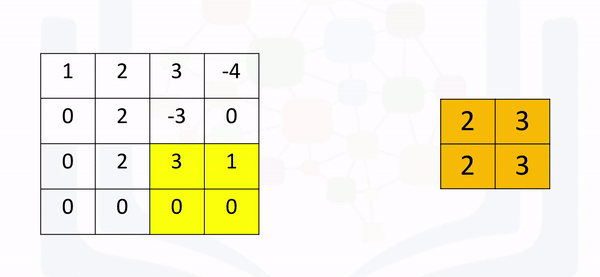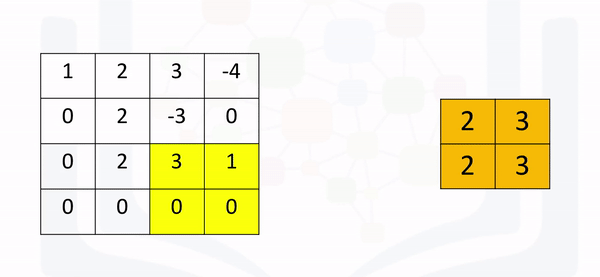
Max pooling simply takes the maximum value in each region. Consider the following image. For the first region, max pooling simply takes the largest element in a yellow region.
The region shifts, and the process is repeated. The process is similar to convolution and is demonstrated in the following figure:
Create a maxpooling object in 2d as follows and perform max pooling as follows:
If the stride is set to None (its defaults setting), the process will simply take the maximum in a prescribed area and shift over accordingly as shown in the following figure:
Here's the code in Pytorch: