## Uncomment and run this cell to install the packages
# !pip install --upgrade dataideaDescriptive Statistics
Descriptive statistics is a branch of statistics that deals with the presentation and summary of data in a meaningful and informative way.
Keywords
descriptive statistics, what is descriptive statistics, Measures of central tendency, mean, median, mode, Measures of variability, range, variance, standard deviation, Measures of distribution shape, skewness, kurtosis, Measures of association, quantify the relationship between variables, coefficients

Descriptive Statistics and Summary Metrics
In this notebook, we will learn to obtain important values that describe our data including:
- Measures of central tendency
- Measures of variability
- Measures of distribution shape
- Measures of association
import pandas as pd
import numpy as np
import scipy as sp
import matplotlib.pyplot as pltThis notebook has been modified to use the Nobel Price Laureates Dataset which you can download from opendatasoft
# load the dataset (modify the path to point to your copy of the dataset)
data = pd.read_csv('../assets/nobel_prize_year.csv')
data = data[data.Gender != 'org'] # removing organizations
data.sample(n=5)| Year | Gender | Category | birth_year | age | |
|---|---|---|---|---|---|
| 505 | 2014 | male | Physics | 1929 | 85 |
| 318 | 1952 | male | Literature | 1885 | 67 |
| 883 | 1933 | male | Literature | 1870 | 63 |
| 481 | 1995 | male | Peace | 1908 | 87 |
| 769 | 2005 | male | Peace | 1942 | 63 |
What is Descriptive Statistics
Descriptive statistics is a branch of statistics that deals with the presentation and summary of data in a meaningful and informative way. Its primary goal is to describe and summarize the main features of a dataset.
Commonly used measures in descriptive statistics include:
Measures of central tendency: These describe the center or average of a dataset and include metrics like mean, median, and mode.
Measures of variability: These indicate the spread or dispersion of the data and include metrics like range, variance, and standard deviation.
Measures of distribution shape: These describe the distribution of data points and include metrics like skewness and kurtosis.
Measures of association: These quantify the relationship between variables and include correlation coefficients.
Descriptive statistics provide simple summaries about the sample and the observations that have been made.
1. Measures of central tendency ie Mean, Median, Mode:
The Center of the Data:
The center of the data is where most of the values are concentrated.
Mean: It is the average value of a dataset calculated by summing all values(numerical) and dividing by the total count.
mean_value = np.mean(data.age)
print("Mean:", mean_value)Mean: 60.21383647798742Median: It is the middle value of a dataset when arranged in ascending order. If there is an even number of observations, the median is the average of the two middle values.
median_value = np.median(data.age)
print("Median:", median_value)Median: 60.0Mode: It is the value that appears most frequently in a dataset.
mode_value = sp.stats.mode(data.age)[0]
print("Mode:", mode_value)Mode: 56Homework:
Other ways to find mode (ie using pandas and numpy)
2. Measures of variability
The Variation of the Data:
The variation of the data is how spread out the data are around the center.
a) Variance and Standard Deviation:
Variance: It measures the spread of the data points around the mean.
# how to implement the variance and standard deviation using numpy
variance_value = np.var(data.age)
print("Variance:", variance_value)Variance: 159.28551085795658Standard Deviation: It is the square root of the variance, providing a measure of the average distance between each data point and the mean.
std_deviation_value = np.std(data.age)
print("Standard Deviation:", std_deviation_value)Standard Deviation: 12.620836377116873Summary
In summary, variance provides a measure of dispersion in squared units, while standard deviation provides a measure of dispersion in the original units of the data
Note!
Smaller variances and standard deviation values mean that the data has values similar to each other and closer to the mean and the vice versa is true
plt.hist(x=data.age, bins=20, edgecolor='black')
# add standard deviation lines
plt.axvline(mean_value, color='red', linestyle='--', label='Mean')
plt.axvline(mean_value+std_deviation_value, color='orange', linestyle='--', label='1st std Dev')
plt.axvline(mean_value-std_deviation_value, color='orange', linestyle='--')
plt.title('Age of Nobel Prize Winners')
plt.ylabel('Frequency')
plt.xlabel('Age')
# Adjust the position of the legend
plt.legend(loc='upper left')
plt.show()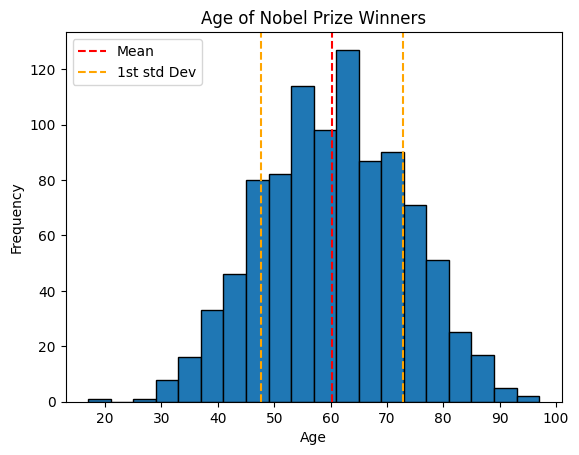
- Range and Interquartile Range (IQR):
Range: It is the difference between the maximum and minimum values in a dataset. It is simplest measure of variation
# One way to obtain range
min_age = min(data.age)
max_age = max(data.age)
age_range = max_age - min_age
print('Range:', age_range)Range: 80# Calculating the range using numpy
range_value = np.ptp(data.age)
print("Range:", range_value)Range: 80Interquartile Range (IQR): It is the range between the first quartile (25th percentile) and the third quartile (75th percentile) of the dataset.
Quartiles:
Calculating Quartiles
The quartiles (Q0,Q1,Q2,Q3,Q4) are the values that separate each quarter.
Between Q0 and Q1 are the 25% lowest values in the data. Between Q1 and Q2 are the next 25%. And so on.
- Q0 is the smallest value in the data.
- Q1 is the value separating the first quarter from the second quarter of the data.
- Q2 is the middle value (median), separating the bottom from the top half.
- Q3 is the value separating the third quarter from the fourth quarter
- Q4 is the largest value in the data.
# Calculate the quartile
quartiles = np.quantile(a=data.age, q=[0, 0.25, 0.5, 0.75, 1])
print('Quartiles:', quartiles)Quartiles: [17. 51. 60. 69. 97.]Percentiles:
Percentiles are values that separate the data into 100 equal parts.
For example, The 95th percentile separates the lowest 95% of the values from the top 5%
- The 25th percentile (P25%) is the same as the first quartile (Q1).
- The 50th percentile (P50%) is the same as the second quartile (Q2) and the median.
- The 75th percentile (P75%) is the same as the third quartile (Q3)
Calculating Percentiles with Python
To get all the percentile values, we can use np.percentile() method and pass in the data, and the list of the percentiles as showed below.
# Getting many percentiles
percentiles = np.percentile(data.age, [25, 50, 75])
print(f'Percentiles: {percentiles}')Percentiles: [51. 60. 69.]To get a single percentile value, we can again use the np.percentile() method and pass in the data, and a the specicific percentile you’re interested in eg:
# Getting one percentile at a time
first_quartile = np.percentile(a=data.age, q=25) # 25th percentile
middle_percentile = np.percentile(data.age, 50)
third_quartile = np.percentile(data.age, 75) # 75th percentile
print('Q1: ', first_quartile)
print('Q2: ', middle_percentile)
print('Q3: ', third_quartile)Q1: 51.0
Q2: 60.0
Q3: 69.0Note!
Note also that we can be able to use the np.quantile() method to calculate the percentiles which makes logical sense as all the values mark a fraction(percentage) of the data
percentiles = np.quantile(a=data.age, q=[0.25, 0.50, 0.75])
print('Percentiles:', percentiles)Percentiles: [51. 60. 69.]Now we can be able to obtain the interquartile range as the difference between the third and first quartiles as predefined.
# obtain the interquartile
iqr_value = third_quartile - first_quartile
print('Interquartile range: ', iqr_value)Interquartile range: 18.0Note: Quartiles and percentiles are both types of quantiles
Summary
While the range gives an overview of the entire spread of the data from lowest to highest, the interquartile range focuses s`pecifically on the spread of the middle portion of the data, making it more robust against outliers.
3. Measures of distribution shape ie Skewness and Kurtosis:
The shape of the Data:
The shape of the data refers to how the data are bounded on either side of the center.
Skewness: It measures the asymmetry of the distribution.
# let's get skew from scipy
skewness_value = sp.stats.skew(data.age)
print("Skewness:", skewness_value)Skewness: -0.028324578326524283How to interpret Skewness:
Positive skewness (> 0) indicates that the tail on the right side of the distribution is longer than the left side (right skewed).
Negative skewness (< 0) indicates that the tail on the left side of the distribution is longer than the right side (left skewed).
# Plot the histogram
# Set density=True for normalized histogram
plt.hist(x=data.age, bins=20, density=True, edgecolor='black')
# Create a normal distribution curve
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = sp.stats.norm.pdf(x, mean_value, std_deviation_value)
plt.plot(x, p, 'k', linewidth=2)
# 'k' indicates black color, you can change it to any color
# Labels and legend
plt.xlabel('Age')
plt.ylabel('Probability Density')
plt.title('Histogram with Normal Distribution Curve')
plt.legend(['Normal Distribution', 'Histogram'])
plt.show()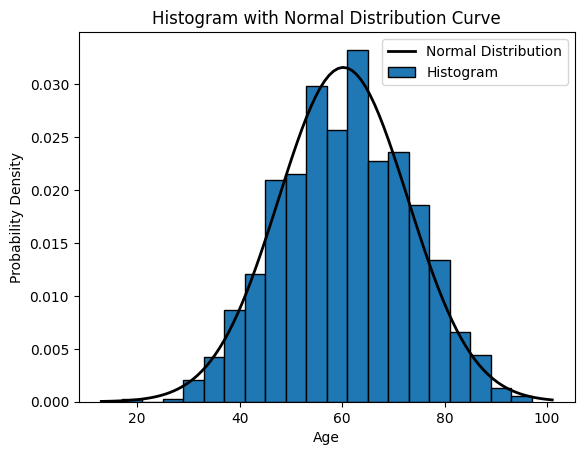
Kurtosis: It measures the peakedness or flatness of the distribution.
# let's get kurtosis from scipy
kurtosis_value = sp.stats.kurtosis(data.age)
print("Kurtosis:", kurtosis_value)Kurtosis: -0.3811155702676823How to interpret Kurtosis:
A kurtosis of 3 indicates the normal distribution (mesokurtic), also known as Gaussian distribution.
Positive kurtosis (> 3) indicates a distribution with heavier tails and a sharper peak than the normal distribution. This is called leptokurtic.
Negative kurtosis (< 3) indicates a distribution with lighter tails and a flatter peak than the normal distribution. This is called platykurtic.
Note!
In simple terms, skewness tells you if your data is leaning more to one side or the other, while kurtosis tells you if your data has heavy or light tails and how sharply it peaks.
4. Measures of association
a). Correlation
Correlation measures the relationship between two numerical variables.
Correlation Matrix
A correlation matrix is simply a table showing the correlation coefficients between variables
Correlation Matrix in Python
We can use the corrcoef() function in Python to create a correlation matrix.
# Generate example data
x = np.array([1, 1, 3, 5, 15])
y = np.array([2, 4, 6, 8, 10])
correlation_matrix = np.corrcoef(x, y)
correlation_matrix_df = pd.DataFrame(
correlation_matrix,
columns=['x', 'y'],
index=['x', 'y']
)
correlation_matrix_df| x | y | |
|---|---|---|
| x | 1.000000 | 0.867722 |
| y | 0.867722 | 1.000000 |
Correlation Coefficient:
The correlation coefficient measures the strength and direction of the linear relationship between two continuous variables.
t ranges from -1 to 1, where:- 1 indicates a perfect positive linear relationship, eg complementary good bread and blueband, battery and torch, fuel and car
- -1 indicates a perfect negative linear relationship, eg substitute goods like tea and coffee
- 0 indicates no linear relationship, eg phones and socks, house and mouse
# Calculate correlation coefficient
correlation = np.corrcoef(x, y)[0, 1]
print("Correlation Coefficient:", correlation)Correlation Coefficient: 0.8677218312746245Correlation vs Causality:
Correlation measures the numerical relationship between two varaibles
A high correlation coefficient (close to 1), does not mean that we can for sure conclude an actual relationship between two variables.
A classic example:
- During the summer, the sale of ice cream at a beach increases
- Simultaneously, drowning accidents also increase as well
Does this mean that increase of ice cream sale is a direct cause of increased drowning accidents?
Measures of Association for Categorical Variables
- Contingency Tables and Chi-square Test for Independence:
Contingency tables are used to summarize the relationship between two categorical variables by counting the frequency of observations for each combination of categories.
Chi-square test for independence determines whether there is a statistically significant association between the two categorical variables.
demo_data = data[['Gender', 'Category']]
# We drop all the missing values just for demonstration purposes
demo_data = demo_data.dropna()Obtain the cross tabulation of Gender and Category. The cross tabulation is also known as the contingency table
# cross tab
gender_category_tab = pd.crosstab(
demo_data.Gender,
demo_data.Category
)
# Let's have a look at the outcome
gender_category_tab| Category | Chemistry | Economics | Literature | Medicine | Peace | Physics |
|---|---|---|---|---|---|---|
| Gender | ||||||
| female | 8 | 2 | 17 | 13 | 18 | 5 |
| male | 181 | 87 | 102 | 212 | 90 | 219 |
Test of Independence:
This test is used to determine whether there is a significant association between two categorical variables.
Formula: \[χ² = \sum \frac{(O_{ij} - E_{ij})^2}{E_{ij}}\] where: - \(O_{ij}\) = Observed frequency for each cell in the contingency table - \(E_{ij}\) = Expected frequency for each cell under the assumption of independence
chi2_stat, p_value, dof, expected = sp.stats.chi2_contingency(gender_category_tab)
print('Chi-square Statistic:', chi2_stat)
print('p-value:', p_value)
print('Degrees of freedom (dof):', dof)
# print('Expected:', expected)Chi-square Statistic: 40.7686907732235
p-value: 1.044840181761602e-07
Degrees of freedom (dof): 5Interpretation of Chi2 Test Results:
- The Chi-square statistic measures the difference between the observed frequencies in the contingency table and the frequencies that would be expected if the variables were independent.
- The p-value is the probability of obtaining a Chi-square statistic as extreme as, or more extreme than, the one observed in the sample, assuming that the null hypothesis is true (i.e., assuming that there is no association between the variables).
- A low p-value indicates strong evidence against the null hypothesis, suggesting that there is a significant association between the variables.
- A high p-value indicates weak evidence against the null hypothesis, suggesting that there is no significant association between the variables.
- Measures of Association for Categorical Variables:
- Measures like Cramer’s V or phi coefficient quantify the strength of association between two categorical variables.
- These measures are based on chi-square statistics and the dimensions of the contingency table.
The formula for Cramer’s V is:
\[V = \sqrt{\frac{χ²}{n(k - 1)}}\]
Where: - \(χ²\) is the chi-square statistic from the chi-square test of independence. - \(n\) is the total number of observations in the contingency table. - \(k\) is the minimum of the number of rows and the number of columns in the contingency table.
Cramer’s V is a normalized measure of association, making it easier to interpret compared to the raw chi-square statistic. A larger value of Cramer’s V indicates a stronger association between the variables.
from dataidea.statistics import cramersVcramersV(contingency_table=gender_category_tab)0.20672318859163366from dataidea.statistics import cramersVCorrectedcramersVCorrected(gender_category_tab)0.19371955249110775Cramer’s V is measure of association between two categorical variables. It ranges from 0 to 1 where:
- 0 indicates no association between the variables
- 1 indicates a perfect association between the variables
Here’s an interpretation of the Cramer’s V:
- Small effect: Around 0.1
- Medium effect: Around 0.3
- Large effect: Around 0.5 or greater
Frequency Tables
Frequency means the number of times a value appears in the data. A table can quickly show us how many times each value appears. If the data has many different values, it is easier to use intervals of values to present them in a table.
Here’s the age of the 934 Nobel Prize winners up until the year 2020. IN the table, each row is an age interval of 10 years
| Age Interval | Frequency |
|---|---|
| 10-19 | 1 |
| 20-29 | 2 |
| 30-39 | 48 |
| 40-49 | 158 |
| 50-59 | 236 |
| 60-69 | 262 |
| 70-79 | 174 |
| 80-89 | 50 |
| 90-99 | 3 |
Note: The intervals for the values are also called bin
Further Reading
Chapter 3 of An Introduction to Statistical Methods and Data Analysis 7th Edition_New