# These are the libraries we are going to use in the lab.
import torch
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits import mplot3d
from dataidea_science.plots import plot_error_surfacesTraining Two Parameter Stochastic Gradient Descent
In this Lab, you will practice training a model by using Stochastic Gradient

Linear regression 1D: Training Two Parameter Stochastic Gradient Descent (SGD)
Objective
- How to use SGD(Stochastic Gradient Descent) to train the model.
Table of Contents
In this Lab, you will practice training a model by using Stochastic Gradient descent.
- Make Some Data
- Create the Model and Cost Function (Total Loss)
- Train the Model:Batch Gradient Descent
- Train the Model:Stochastic gradient descent
- Train the Model:Stochastic gradient descent with Data Loader
Estimated Time Needed: 30 min
Preparation
We’ll need the following libraries:
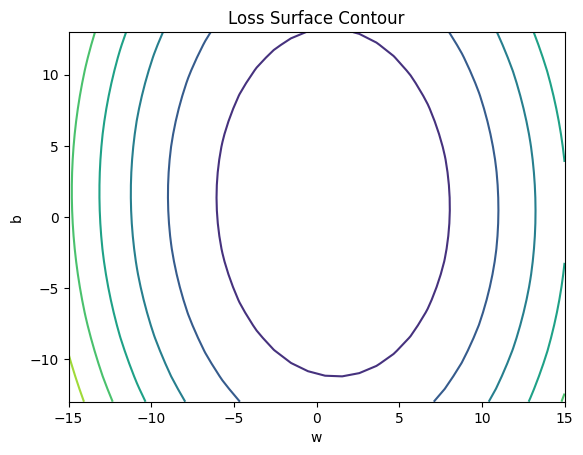
The class plot_error_surfaces is just to help you visualize the data space and the parameter space during training and has nothing to do with PyTorch.
Make Some Data
Set random seed:
# Set random seed
torch.manual_seed(1)<torch._C.Generator at 0x79c1633e7c10>Generate values from -3 to 3 that create a line with a slope of 1 and a bias of -1. This is the line that you need to estimate. Add some noise to the data:
# Setup the actual data and simulated data
X = torch.arange(-3, 3, 0.1).view(-1, 1)
f = 1 * X - 1
Y = f + 0.1 * torch.randn(X.size())Plot the results:
# Plot out the data dots and line
from dataidea.models import *Create the Model and Cost Function (Total Loss)
Define the forward function:
# Define the forward function
def forward(x):
return w * x + bDefine the cost or criterion function (MSE):
# Define the MSE Loss function
def criterion(yhat, y):
return torch.mean((yhat - y) ** 2)Create a plot_error_surfaces object to visualize the data space and the parameter space during training:
# Create plot_error_surfaces for viewing the data
get_surface = plot_error_surfaces(15, 13, X, Y, 30)<Figure size 640x480 with 0 Axes>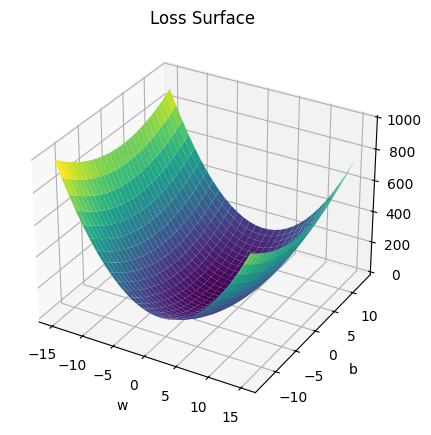
Train the Model: Batch Gradient Descent
Create model parameters w, b by setting the argument requires_grad to True because the system must learn it.
# Define the parameters w, b for y = wx + b
w = torch.tensor(-15.0, requires_grad = True)
b = torch.tensor(-10.0, requires_grad = True)Set the learning rate to 0.1 and create an empty list LOSS for storing the loss for each iteration.
# Define learning rate and create an empty list for containing the loss for each iteration.
lr = 0.1
LOSS_BGD = []Define train_model function for train the model.
# The function for training the model
def train_model(iter):
# Loop
for epoch in range(iter):
# make a prediction
Yhat = forward(X)
# calculate the loss
loss = criterion(Yhat, Y)
# Section for plotting
get_surface.set_para_loss(w.data.tolist(), b.data.tolist(), loss.tolist())
get_surface.plot_ps()
# store the loss in the list LOSS_BGD
LOSS_BGD.append(loss)
# backward pass: compute gradient of the loss with respect to all the learnable parameters
loss.backward()
# update parameters slope and bias
w.data = w.data - lr * w.grad.data
b.data = b.data - lr * b.grad.data
# zero the gradients before running the backward pass
w.grad.data.zero_()
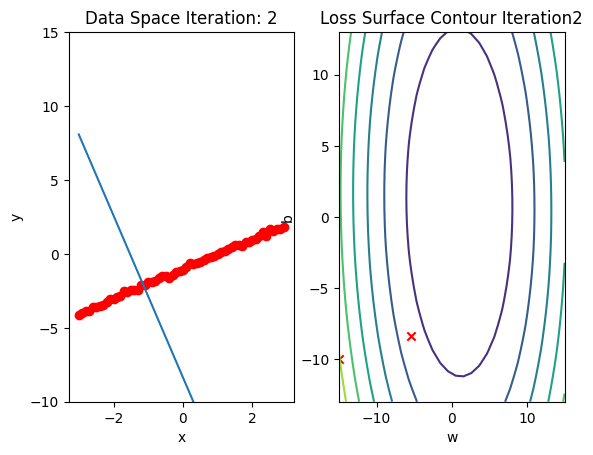
b.grad.data.zero_()Run 10 epochs of batch gradient descent: bug data space is 1 iteration ahead of parameter space.
# Train the model with 10 iterations
train_model(10)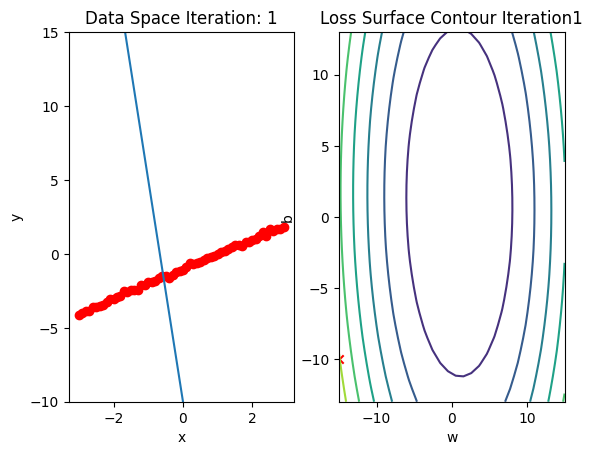
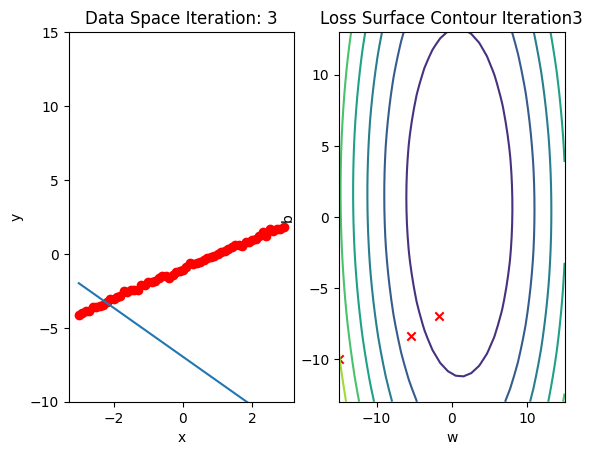
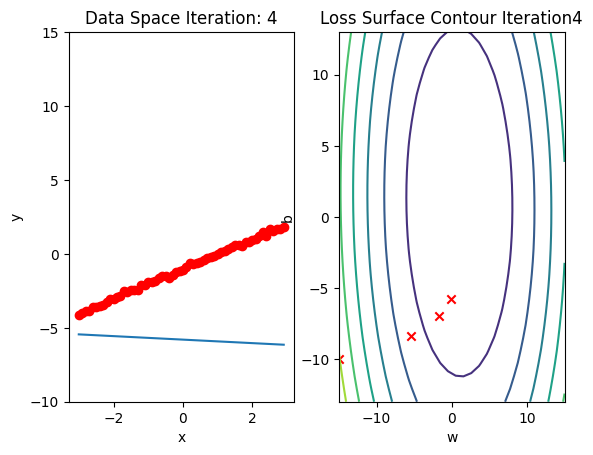
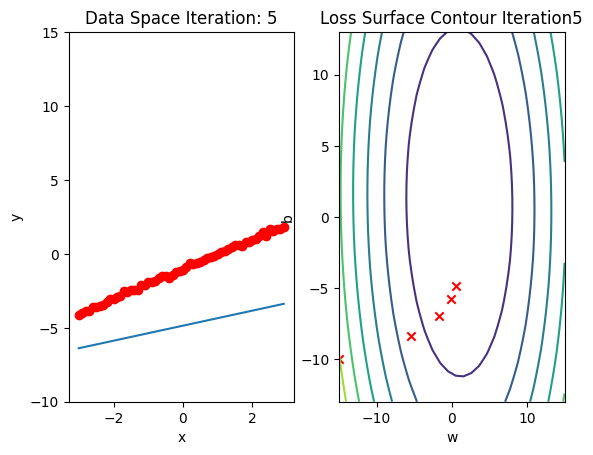
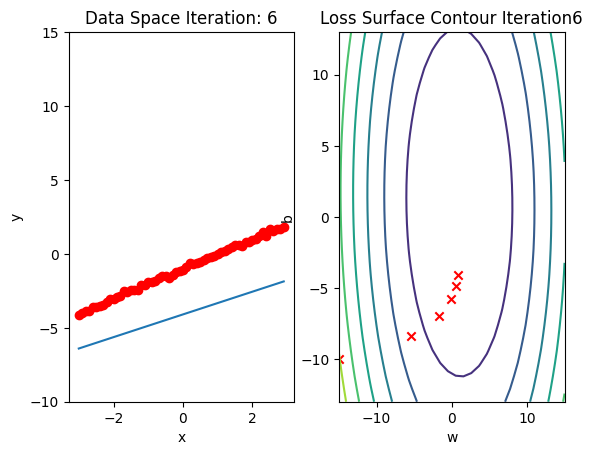
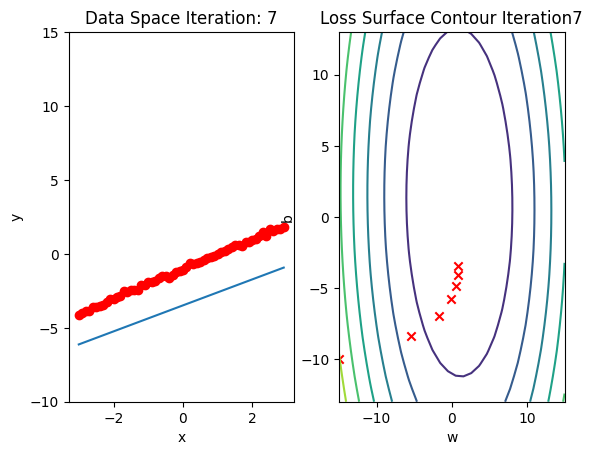
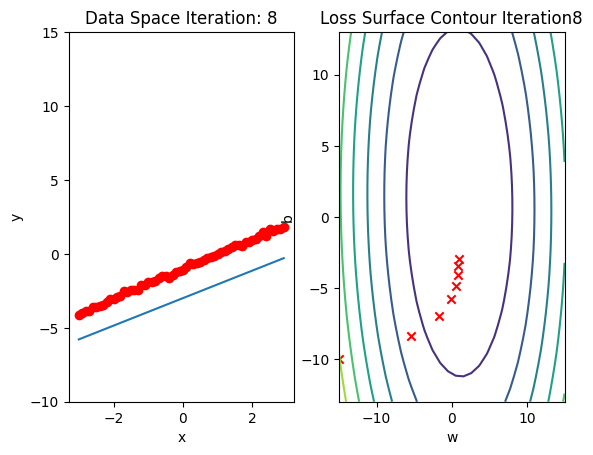
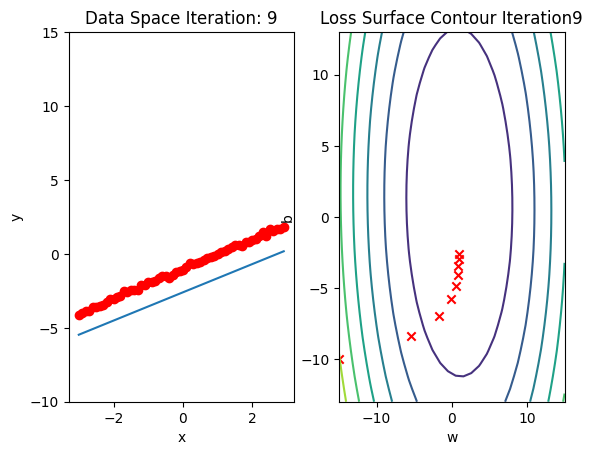
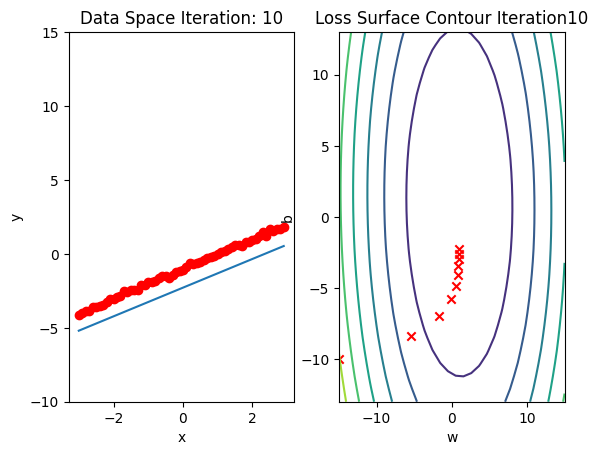
Train the Model: Stochastic Gradient Descent
Create a plot_error_surfaces object to visualize the data space and the parameter space during training:
# Create plot_error_surfaces for viewing the data
get_surface = plot_error_surfaces(15, 13, X, Y, 30, go = False)Define train_model_SGD function for training the model.
# The function for training the model
LOSS_SGD = []
w = torch.tensor(-15.0, requires_grad = True)
b = torch.tensor(-10.0, requires_grad = True)
def train_model_SGD(iter):
# Loop
for epoch in range(iter):
# SGD is an approximation of out true total loss/cost, in this line of code we calculate our true loss/cost and store it
Yhat = forward(X)
# store the loss
LOSS_SGD.append(criterion(Yhat, Y).tolist())
for x, y in zip(X, Y):
# make a pridiction
yhat = forward(x)
# calculate the loss
loss = criterion(yhat, y)
# Section for plotting
get_surface.set_para_loss(w.data.tolist(), b.data.tolist(), loss.tolist())
# backward pass: compute gradient of the loss with respect to all the learnable parameters
loss.backward()
# update parameters slope and bias
w.data = w.data - lr * w.grad.data
b.data = b.data - lr * b.grad.data
# zero the gradients before running the backward pass
w.grad.data.zero_()
b.grad.data.zero_()
#plot surface and data space after each epoch
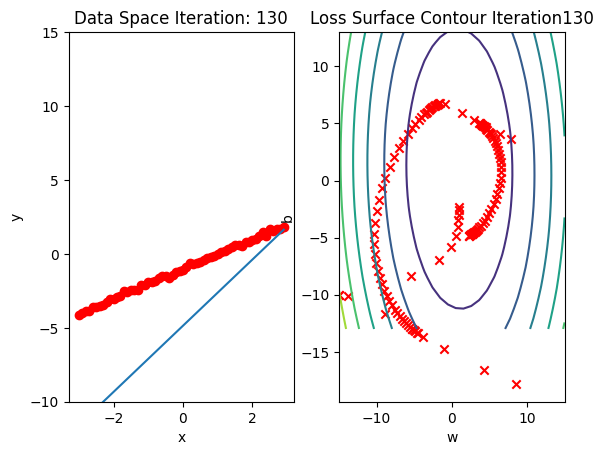
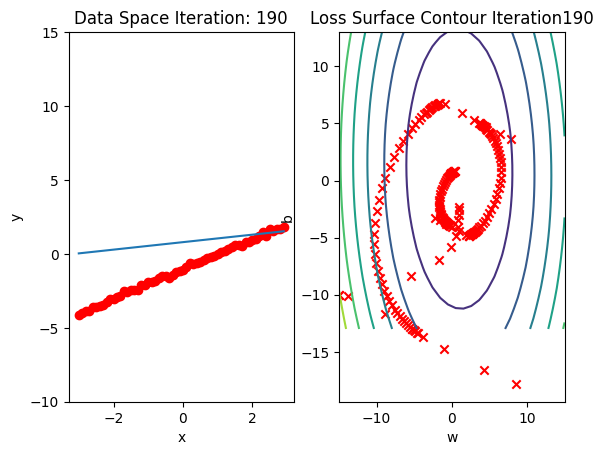
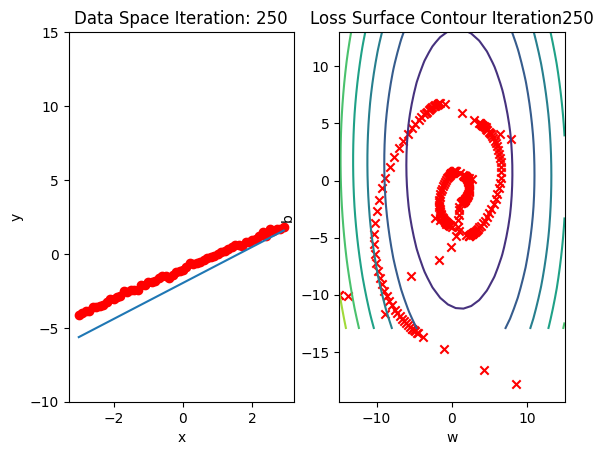
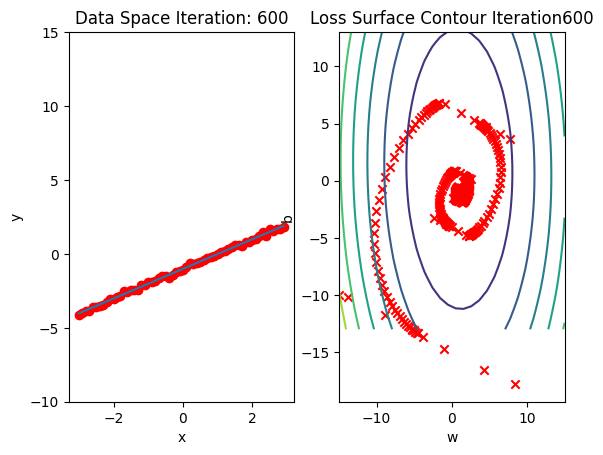
get_surface.plot_ps()Run 10 epochs of stochastic gradient descent: bug data space is 1 iteration ahead of parameter space.
# Train the model with 10 iterations
train_model_SGD(10)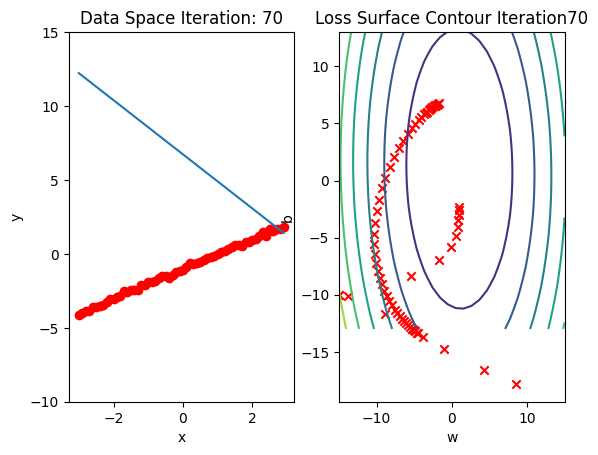
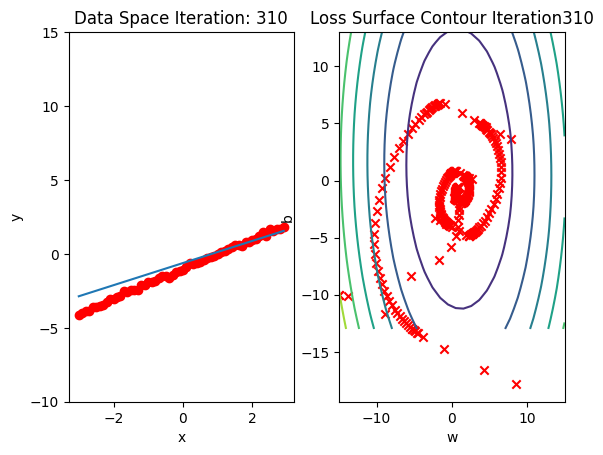
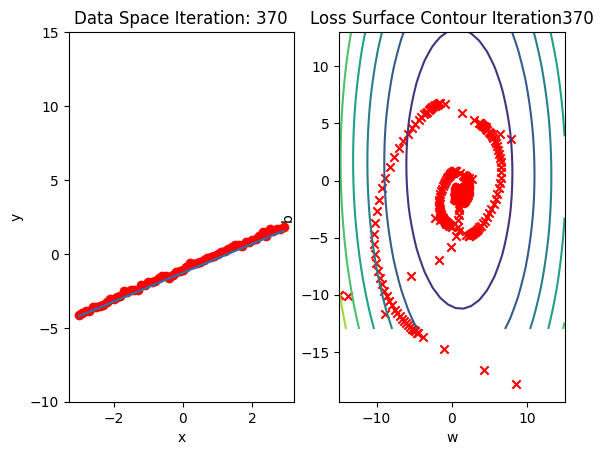
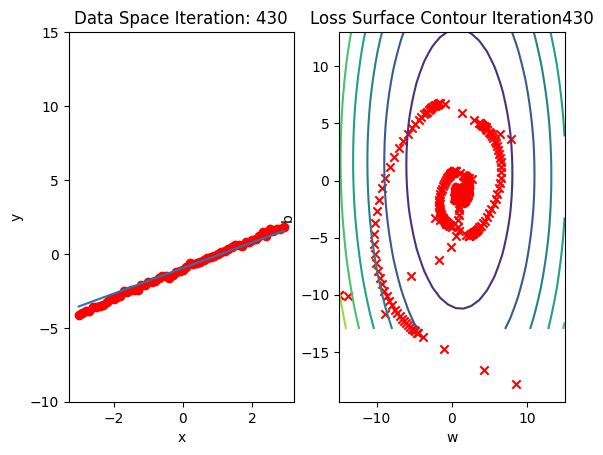
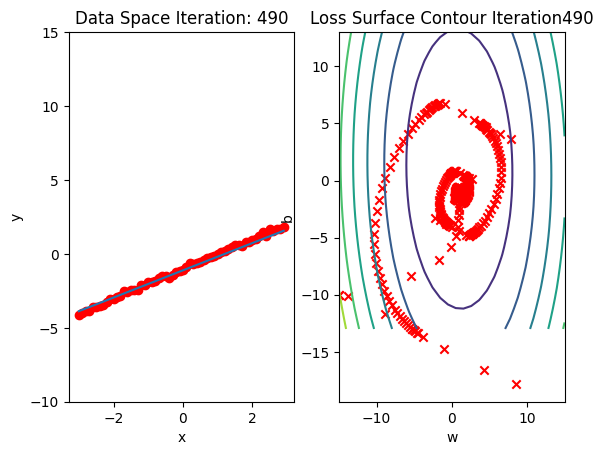
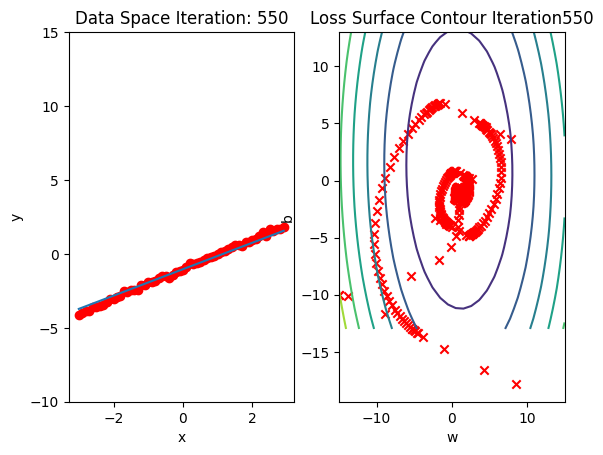
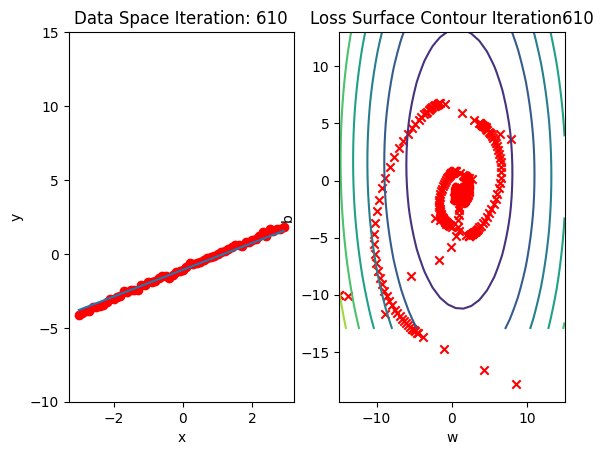
Compare the loss of both batch gradient descent as SGD.
LOSS_BGD_ = [loss.item() for loss in LOSS_BGD]# Plot out the LOSS_BGD and LOSS_SGD
plt.plot(LOSS_BGD_,label = "Batch Gradient Descent")
plt.plot(LOSS_SGD,label = "Stochastic Gradient Descent")
plt.xlabel('epoch')
plt.ylabel('Cost/ total loss')
plt.legend()
plt.show()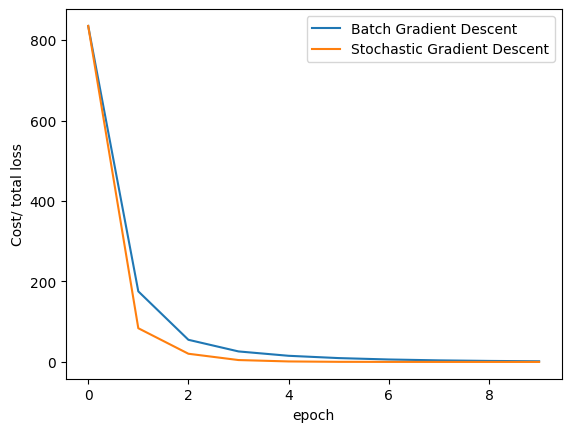
SGD with Dataset DataLoader
Import the module for building a dataset class:
# Import the library for DataLoader
from torch.utils.data import Dataset, DataLoaderCreate a dataset class:
# Dataset Class
class Data(Dataset):
# Constructor
def __init__(self):
self.x = torch.arange(-3, 3, 0.1).view(-1, 1)
self.y = 1 * self.x - 1
self.len = self.x.shape[0]
# Getter
def __getitem__(self,index):
return self.x[index], self.y[index]
# Return the length
def __len__(self):
return self.lenCreate a dataset object and check the length of the dataset.
# Create the dataset and check the length
dataset = Data()
print("The length of dataset: ", len(dataset))The length of dataset: 60Obtain the first training point:
# Print the first point
x, y = dataset[0]
print("(", x, ", ", y, ")")( tensor([-3.]) , tensor([-4.]) )Similarly, obtain the first three training points:
# Print the first 3 point
x, y = dataset[0:3]
print("The first 3 x: ", x)
print("The first 3 y: ", y)The first 3 x: tensor([[-3.0000],
[-2.9000],
[-2.8000]])
The first 3 y: tensor([[-4.0000],
[-3.9000],
[-3.8000]])Create a plot_error_surfaces object to visualize the data space and the parameter space during training:
# Create plot_error_surfaces for viewing the data
get_surface = plot_error_surfaces(15, 13, X, Y, 30, go = False)Create a DataLoader object by using the constructor:
# Create DataLoader
trainloader = DataLoader(dataset = dataset, batch_size = 1)Define train_model_DataLoader function for training the model.
# The function for training the model
w = torch.tensor(-15.0,requires_grad=True)
b = torch.tensor(-10.0,requires_grad=True)
LOSS_Loader = []
def train_model_DataLoader(epochs):
# Loop
for epoch in range(epochs):
# SGD is an approximation of out true total loss/cost, in this line of code we calculate our true loss/cost and store it
Yhat = forward(X)
# store the loss
LOSS_Loader.append(criterion(Yhat, Y).tolist())
for x, y in trainloader:
# make a prediction
yhat = forward(x)
# calculate the loss
loss = criterion(yhat, y)
# Section for plotting
get_surface.set_para_loss(w.data.tolist(), b.data.tolist(), loss.tolist())
# Backward pass: compute gradient of the loss with respect to all the learnable parameters
loss.backward()
# Updata parameters slope
w.data = w.data - lr * w.grad.data
b.data = b.data - lr* b.grad.data
# Clear gradients
w.grad.data.zero_()
b.grad.data.zero_()
#plot surface and data space after each epoch
get_surface.plot_ps()Run 10 epochs of stochastic gradient descent: bug data space is 1 iteration ahead of parameter space.
# Run 10 iterations
train_model_DataLoader(10)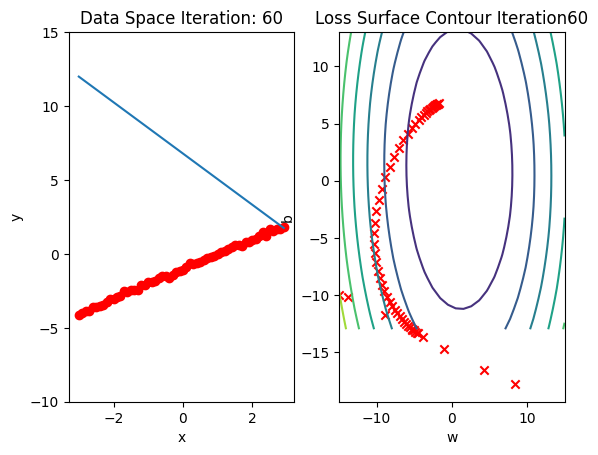
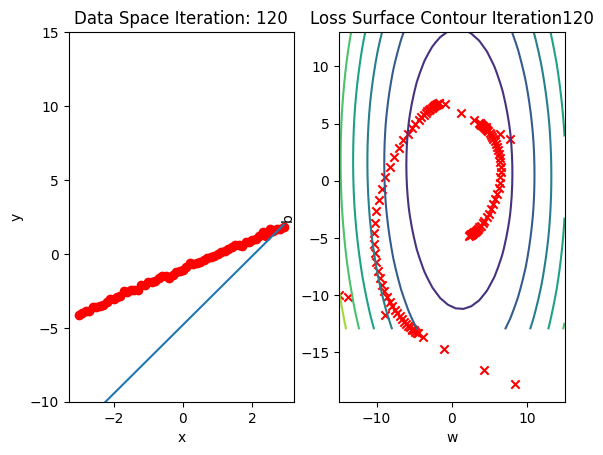
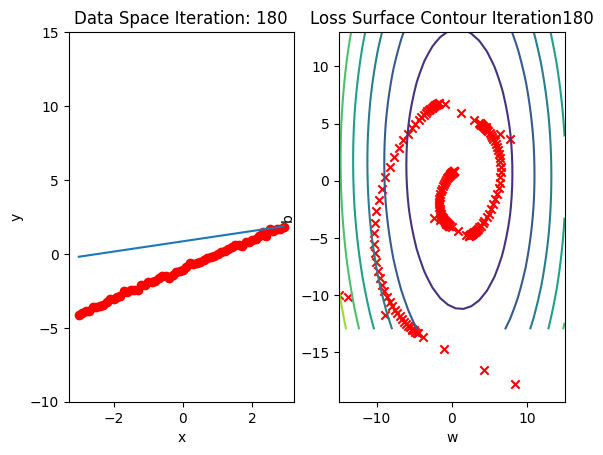
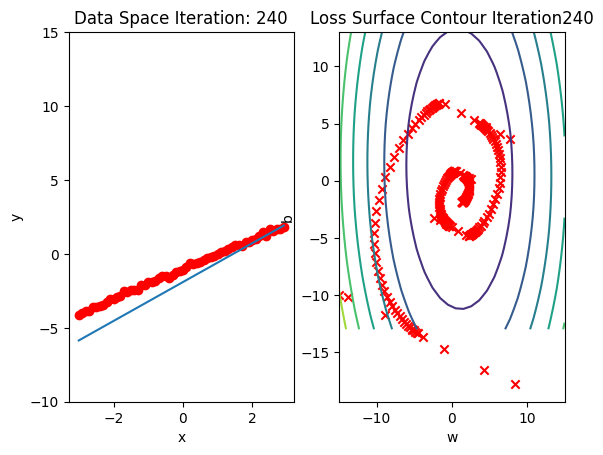
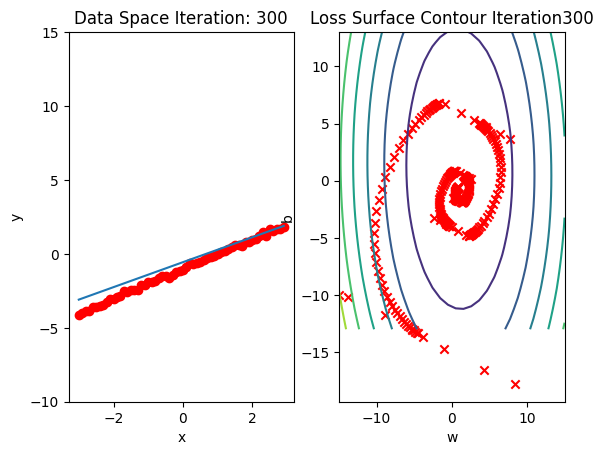
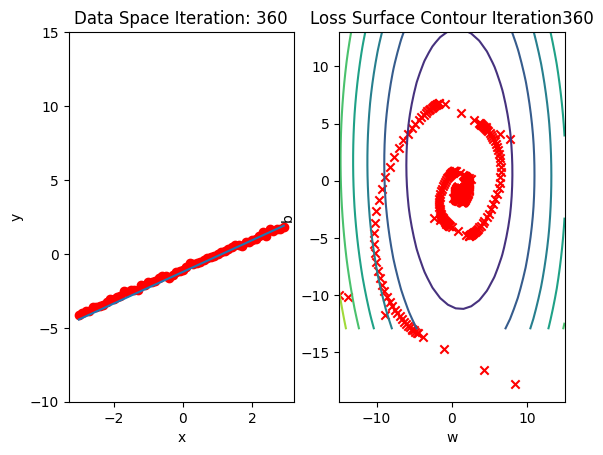
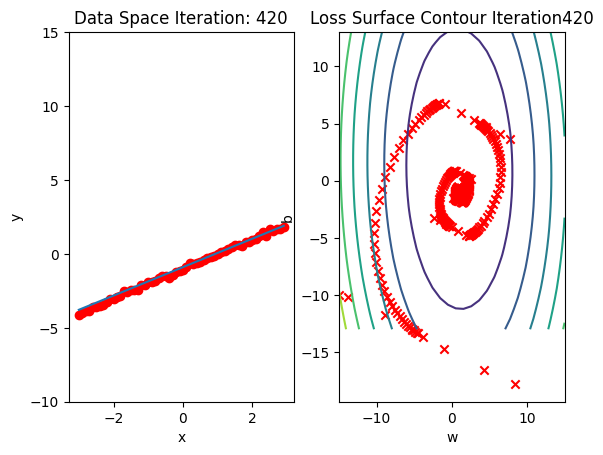
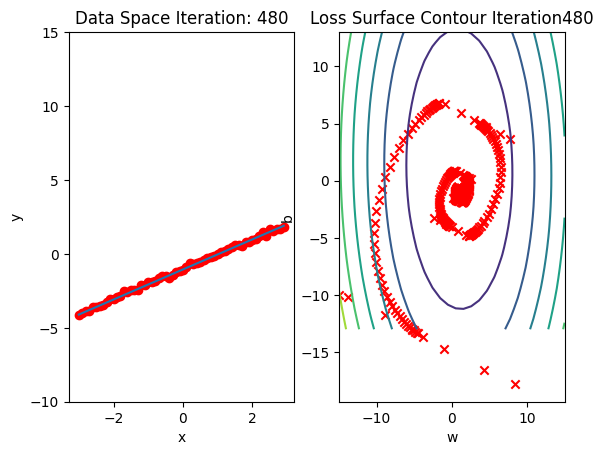
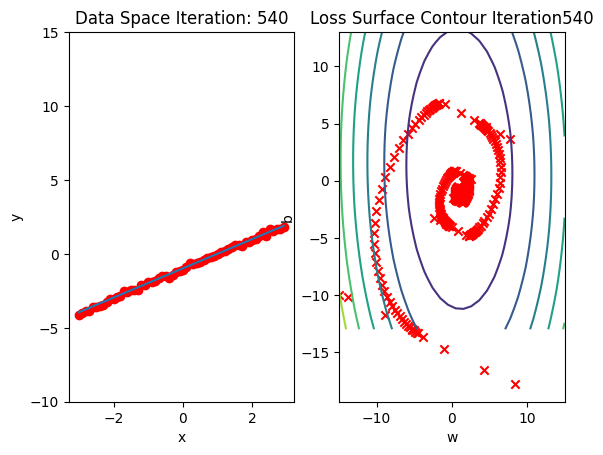
Compare the loss of both batch gradient decent as SGD. Note that SGD converges to a minimum faster, that is, it decreases faster.
# Plot the LOSS_BGD and LOSS_Loader
plt.plot(LOSS_BGD_,label="Batch Gradient Descent")
plt.plot(LOSS_Loader,label="Stochastic Gradient Descent with DataLoader")
plt.xlabel('epoch')
plt.ylabel('Cost/ total loss')
plt.legend()
plt.show()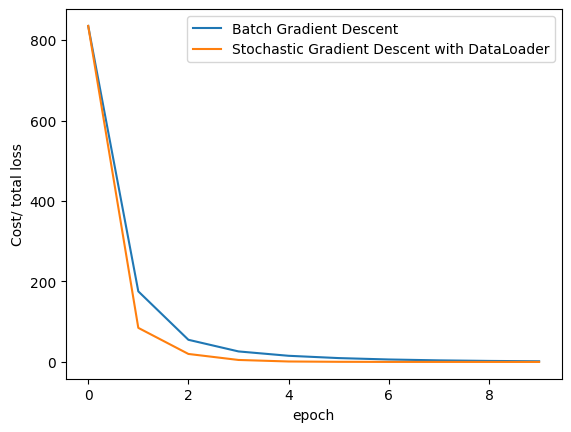
Practice
For practice, try to use SGD with DataLoader to train model with 10 iterations. Store the total loss in LOSS. We are going to use it in the next question.
# Practice: Use SGD with trainloader to train model and store the total loss in LOSS
LOSS = []
w = torch.tensor(-12.0, requires_grad = True)
b = torch.tensor(-10.0, requires_grad = True)Double-click here for the solution.
Plot the total loss
# Practice: Plot the total loss using LOSS
# Type your code hereDouble-click here for the solution.
Back to top