import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
from scipy import ndimage, miscActivation function and Maxpooling
In this lab, you will learn two important components in building a convolutional neural network.
Keywords
Training Two Parameter, Mini-Batch Gradient Decent, Training Two Parameter Mini-Batch Gradient Decent

Objective for this Notebook
- Learn how to apply an activation function.
- Learn about max pooling
Import the following libraries:
Activation Functions
Just like a neural network, you apply an activation function to the activation map as shown in the following image:
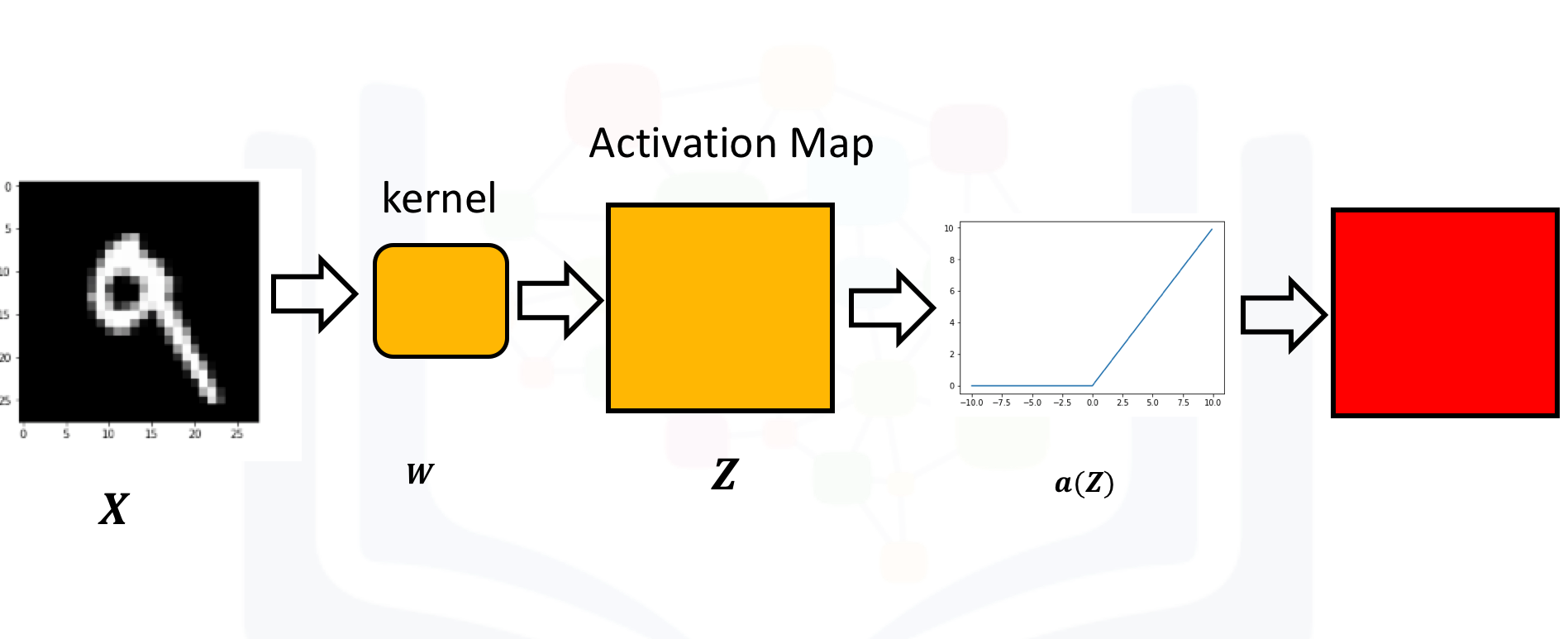
Create a kernel and image as usual. Set the bias to zero:
conv = nn.Conv2d(in_channels=1, out_channels=1,kernel_size=3)
Gx=torch.tensor([[1.0,0,-1.0],[2.0,0,-2.0],[1.0,0,-1.0]])
conv.state_dict()['weight'][0][0]=Gx
conv.state_dict()['bias'][0]=0.0
conv.state_dict()OrderedDict([('weight',
tensor([[[[ 1., 0., -1.],
[ 2., 0., -2.],
[ 1., 0., -1.]]]])),
('bias', tensor([0.]))])image=torch.zeros(1,1,5,5)
image[0,0,:,2]=1
imagetensor([[[[0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0.]]]])The following image shows the image and kernel:
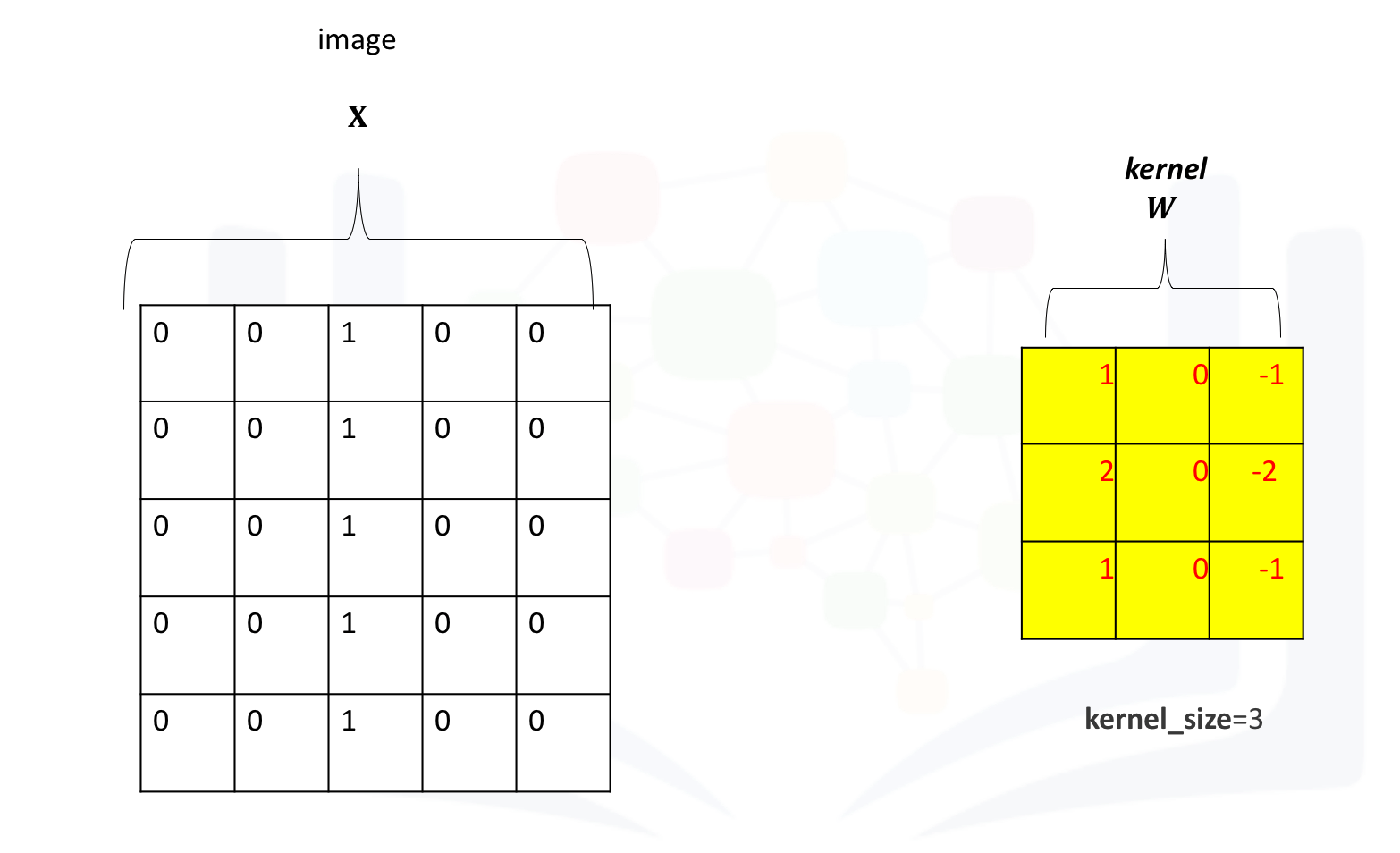
Apply convolution to the image:
Z=conv(image)
Ztensor([[[[-4., 0., 4.],
[-4., 0., 4.],
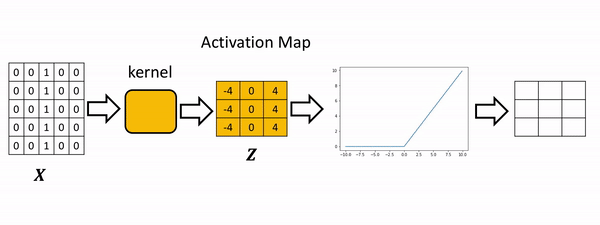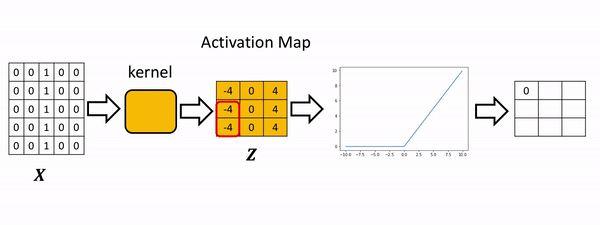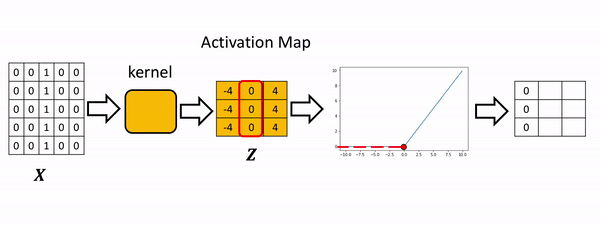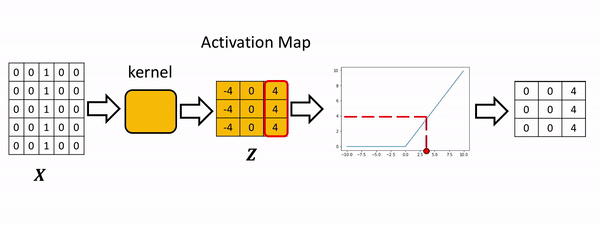
[-4., 0., 4.]]]], grad_fn=<ConvolutionBackward0>)Apply the activation function to the activation map. This will apply the activation function to each element in the activation map.
A=torch.relu(Z)
Atensor([[[[0., 0., 4.],
[0., 0., 4.],
[0., 0., 4.]]]], grad_fn=<ReluBackward0>)relu = nn.ReLU()
relu(Z)tensor([[[[0., 0., 4.],
[0., 0., 4.],
[0., 0., 4.]]]], grad_fn=<ReluBackward0>)The process is summarized in the the following figure. The Relu function is applied to each element. All the elements less than zero are mapped to zero. The remaining components do not change.
Max Pooling
Consider the following image:
image1=torch.zeros(1,1,4,4)
image1[0,0,0,:]=torch.tensor([1.0,2.0,3.0,-4.0])
image1[0,0,1,:]=torch.tensor([0.0,2.0,-3.0,0.0])
image1[0,0,2,:]=torch.tensor([0.0,2.0,3.0,1.0])
image1tensor([[[[ 1., 2., 3., -4.],
[ 0., 2., -3., 0.],
[ 0., 2., 3., 1.],
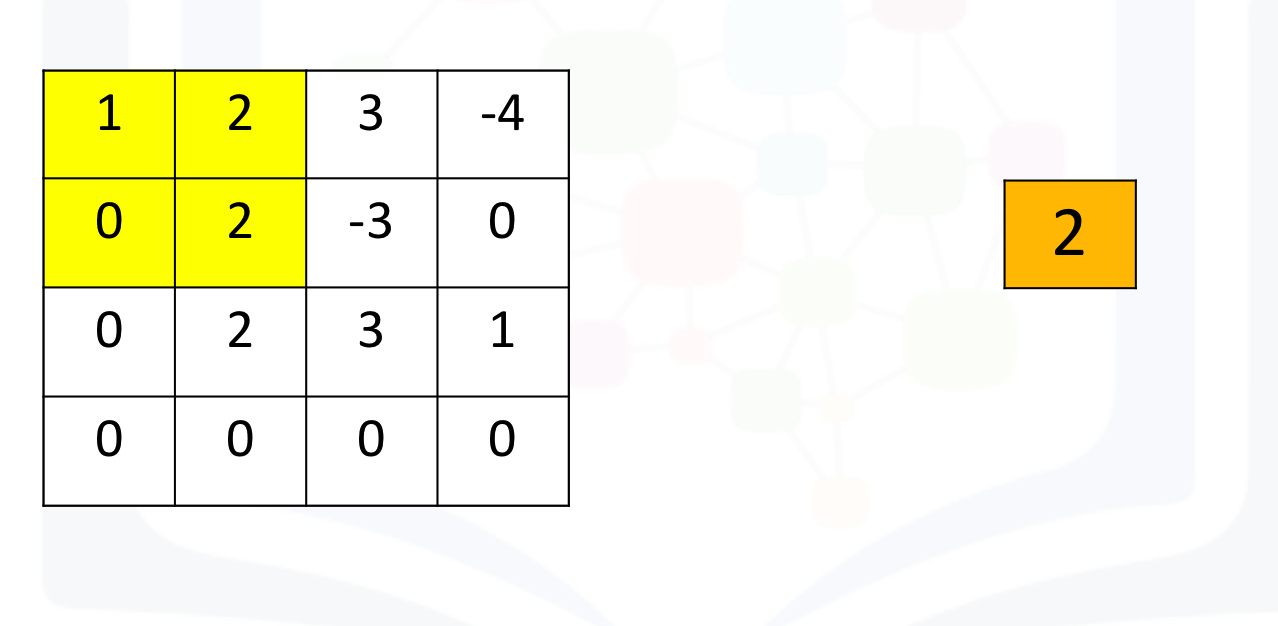
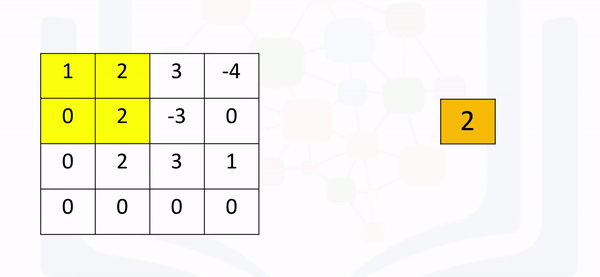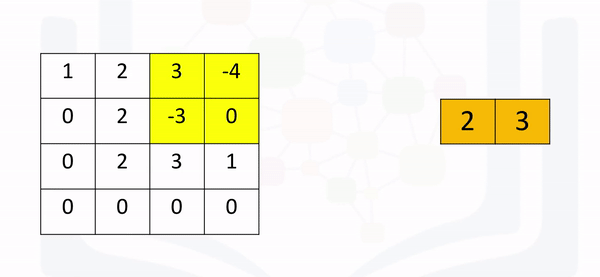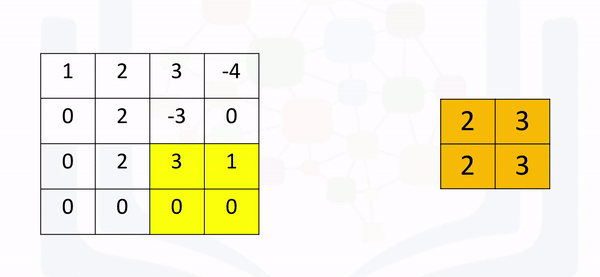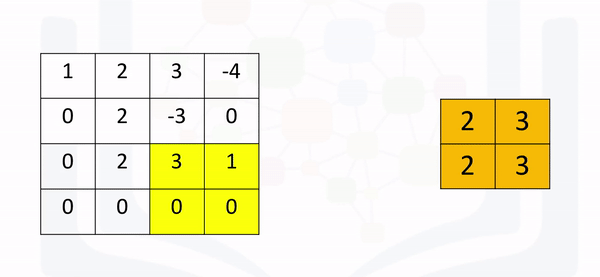
[ 0., 0., 0., 0.]]]])Max pooling simply takes the maximum value in each region. Consider the following image. For the first region, max pooling simply takes the largest element in a yellow region.
The region shifts, and the process is repeated. The process is similar to convolution and is demonstrated in the following figure:
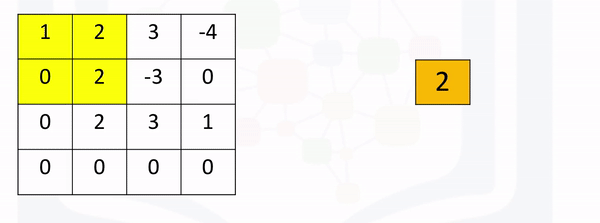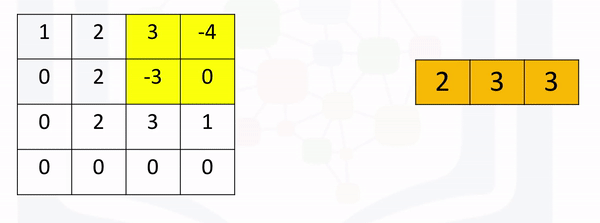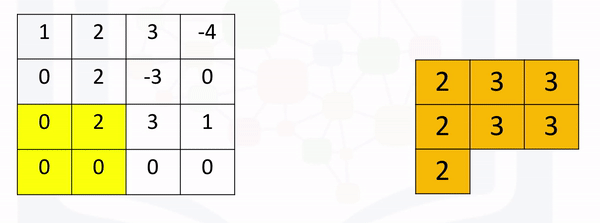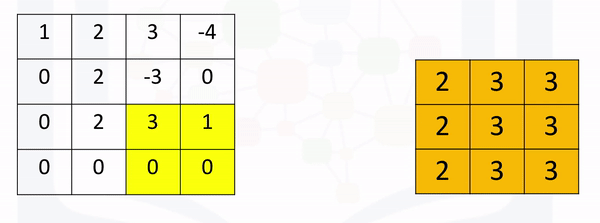
Create a maxpooling object in 2d as follows and perform max pooling as follows:
max1=torch.nn.MaxPool2d(2,stride=1)
max1(image1)tensor([[[[2., 3., 3.],
[2., 3., 3.],
[2., 3., 3.]]]])If the stride is set to None (its defaults setting), the process will simply take the maximum in a prescribed area and shift over accordingly as shown in the following figure:
Here’s the code in Pytorch: